기존 seq2seq에서는 Encoder쪽에서 모든 입력(여러 단어)을 단 하나의 고정 길이의 벡터 \(\textbf{h}\)로 변환하여 Decoder쪽으로 넘겼다.
그러다보니 긴 문장의 경우 중요한 정보(특히 초반 정보)가 누락 될 가능성이 있었다.
따라서 각 시점의 모든 정보를 각각의 \(\textbf{h}\)로 변환하여 Decoder쪽으로 보내는 개선을 고안하게 되었다.
하지만 모든 정보를 넘기게 되면 정보의 과부하가 생길 수 있으므로, 거기서 중요한 정보만 집중 할 수 있는 기술이 Attention이다.
Encoder의 개선
기존의 하나의 벡터에 모든 입력 정보를 담아야만 했던 Encoder를 개선하기 위해 다음과 같은 작업을 시행한다.
아래 그림과 같이 입력 문장의 길이 만큼의 벡터를 만드는 것이다. (그렇다고 입력 문장의 최대 길이가 무제한이라는 얘기는 아니다)
사실 새롭게 벡터를 만든다기보다 매 시점에 위쪽으로 출력되는 \(\textbf{h}\)를 모은 것
이렇게 되면 훨씬 많은 정보를 Decoder에 넘길 수 있다.
Decoder 개선 1
기존 Decoder는 Encoder의 LSTM 계층의 마지막 은닉 상태만을 이용했다.
기존 seq2seq 구조
그런데 사람이 문장을 번역할 때, 특정 중요한 단어에 주목하여 번역을 할 때가 있다. 예를 들어, “나는 고양이로소이다”를 번역한다면, “고양이=cat”이라는 관계에 주목하여 번역을 하게 된다.
따라서 seq2seq에서도 ‘입력과 출력의 여러 단어 중 어떤 단어끼리 서로 더욱 관련이 있는지’ 대응 관계를 파악하는 것이 중요하다
즉, ‘Target 단어’와 대응 관계에 있는 ‘Source 단어’의 정보를 적절히 골라내어 번역을 수행하는 것이 필요하다.
이렇게 필요한 정보를 적절히 참조하는 구조를 어텐션이라고 한다. 대략적인 방식은 다음과 같다.
위에서처럼 ‘어떤 계산’을 통해서 각 시점별로 중요한 정보를 \(\textbf{hs}\)로부터 골라내는 것이다.
하지만 여기서 특정 정보(벡터)만을 쏙 선택하는 작업은 미분할 수 없다(마치 Sampling 과정을 미분 할 수 없듯이)
따라서, ‘하나를 선택’하는 것이 아니라 ‘모든 것을 선택’하고 각 단어의 중요도를 나타내는 ‘가중치’를 별도로 계산하도록 한다(확실히 설명이 기발하긴 하다..)
위에서보듯 \(\textbf{a}\)라는 가중치를 만들어서 \(\textbf{hs}\)와의 weighted sum을 구하여 최종적으로 특정 단어의 정보가 담긴(attention 된) 새로운 벡터를 얻을 수 있다(a는 총 합이 1인 확률분포)
그리고 \(\textbf{a}\)와 \(\textbf{hs}\)를 곱하고 더해서 벡터의 가중합을 만든다. 여기서는 맥락 벡터(context vector)라고 부른다. 위 예시에서는 ‘나’라는 글자의 가중치가 0.8로 높은데, 이 값은 학습에 의해서 적절한 값으로 수정이 된다(번역 성능 향상에 도움이 되는 방향으로)
Decoder 개선 2
각 단어의 중요도를 나타내는 가중치 \(\textbf{a}\)는 그럼 어떻게 학습시킬까?
미리 정답부터 말하자면 가중치 \(textbf{a}\)는 사실 Encoder 쪽 벡터인 \(\textbf{hs}\)와 Decoder 쪽의 매 타임스텝의 \(\textbf{h}\)간의 유사도를 의미하는 것이다. 즉, 두 벡터간 유사도가 크면 높은 가중치를 갖고, 낮으면 낮은 가중치를 갖게 되는 것. ‘유사도 = 중요도’로 해석하는 것이 좀 부자연스럽기는 해도 Transformer에서도 그렇고 인공지능 쪽에서는 여러 분야에서 비슷한 방식으로 학습을 하는 것 같다.
우선 Decoder의 첫 번째 LSTM 계층이 은닉 상태 벡터를 처리하는 과정을 살펴보면 다음과 같다.
위 그림에서 나온 \(\textbf{hs}\)와 \(\textbf{h}\)의 내적을 통해서 유사도 \(\textbf{S}\)(score)를 구한다.
그리고 이렇게 나온 Score를 Softmax를 통해서 합이 1이되도록 정규화 한다. 그리고 그 값을 가중치 \(\textbf{a}\)로 사용하게 된다.
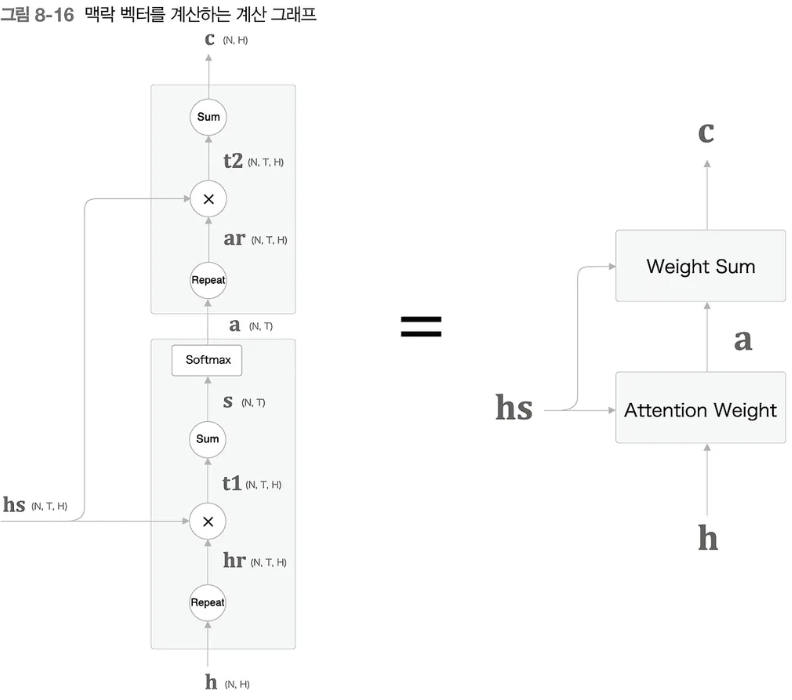
\(\textbf{a}\)를 구하는 과정을 계산 그래프로 그리면 다음과 같다 (N=배치, T=글자 수, H=은닉 벡터 차원), repeat=브로드캐스팅 과정
Decoder 개선 3
앞에서 설명한 Attention Weight와 Weight Sum을 활용한 맥락 벡터를 구하는 과정을 계산 그래프로 나타내면 다음과 같다.
위 과정을 간단히 줄여서 Attention 계층이라고 부르자
이 Attention 계층을 LSTM 계층과 Affine 계층 사이에 삽입하면 구현은 끝이다.
Attention 계층이 추가된 Decoder의 계층을 보면 다음과 같다.
Attention 계층에는 Encoder의 출력인 \(\textbf{hs}\)와 Decoder의 특정 시점의 은닉 상태 벡터인 \(\textbf{h}\)가 입력이 되고, Attention이 추가 된 맥락 벡터가 계산되어 Affine 계층으로 전해진다.
Affine 계층으로는 Attention의 output과 \(\textbf{h}\) 가 Concat 되어 입력된다.
어텐션을 갖춘 seq2seq 구현
Decoder 구현체
‘문자로 표시된 날짜’를 ‘숫자로 표시하는 예시’에 대한 어텐션 시각화 (september 27, 1994 → 1994-09-27)
Attention 계층은 각 시각의 Attention 가중치 a를 인스턴스 변수로 보관하고 있으므로, 이를 시각화 할 수 있다.
무슨 말이냐면, 예를 들어, Decoding을 수행할 때, 매 시점마다 Decoder쪽에서 나온 매 시점의 h와 Encoder 쪽에서 전해진 hs간의 내적을 통한 합이 1인 가중치 a 벡터가 생긴다. 그리고 그게 모든 시점마다 생기므로 (시점 X a) 만큼의 2차원 매트릭스가 생기고, 그걸 시각화 하면 아래와 같아진다.
입력의 1983, 26과 출력의 1983, 26의 Attention Score가 밝은 것을 볼 수 있다.
또한 입력의 AUGUST와 출력의 08의 Attention Score 또한 밝다.
이러한 결과를 통해, 모델의 Attention이 잘 동작하는 것을 알 수 있고, 결과를 인간이 이해할 수 있게 되었다고 할 수 있다.(explainable)
어텐션에 관한 남은 이야기
양방향 RNN
기존 LSTM, RNN에서는 특정 단어를 Encoding 할 때 먼저 등장(왼쪽)한 단어들만 Encoding 할 수 있었다. 그러나 오른쪽에 있는 글자들도 함께 Encoding 한다면 더 균형잡힌 정보를 담을 수 있을 것이다.
단방향(Left to Right) LSTM(좌) vs 양방향 LSTM(우)
그림 8-30에서 보듯, 기존의 LSTM계층에 역방향으로 처리하는 LSTM 계층을 추가한다. 그리고 기존 LSTM의 벡터와 역방향 LSTM 계층의 벡터를 Concat(혹은 더하거나 평균)을 해서 최종 은닉 상태 벡터로 처리 할 수 있다.
양방향 LSTM을 구현하기 위해선, 입력 문장의 단어들을 반대 순서로 나열해서 입력시키는 층을 하나 더 만들면 된다.
Attention 계층 사용 방법
기존에는 왼쪽 처럼 Attention 계층을 LSTM와 Affine 사이에 두었으나, 반드시 그럴 필요는 없다.
오른쪽 그림처럼 Attention 계층의 출력(맥락 벡터)이 다음 시각의 LSTM 계층으로 입력되도록 구현 할 수도 있다(Attention 계층의 입력은 같음)
이처럼 Attention 계층의 위치를 달리하는 것이 성능에 어떤 결과를 미칠지는 실험을 통해 검증할 수 밖에 없다.
seq2seq 심층화와 skip 연결
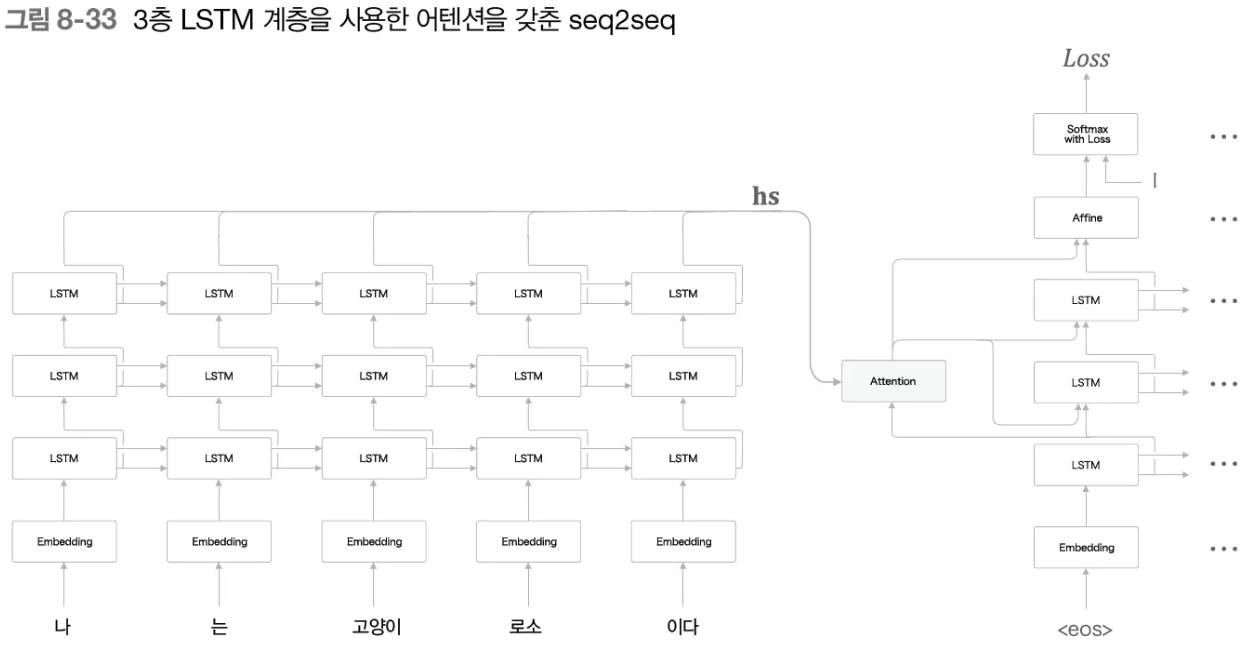
attention이 추가된 seq2seq 모델의 성능을 높이기 위해, LSTM 계층 또한 깊게 쌓을 수 있다. attention에서도 마찬가지로 깊게 쌓으면 표현력 높은 모델을 만들 수 있기 때문이다.
Encoder와 Decoder에서는 같은 층수의 LSTM 계층을 이용하는 것이 일반적이다.
위 그림에서, Decoder 쪽에서는 Attention 계층이 하나만 사용되었지만 이는 예시일 뿐이고 여러개의 Attention 계층을 사용할 수도 있다.
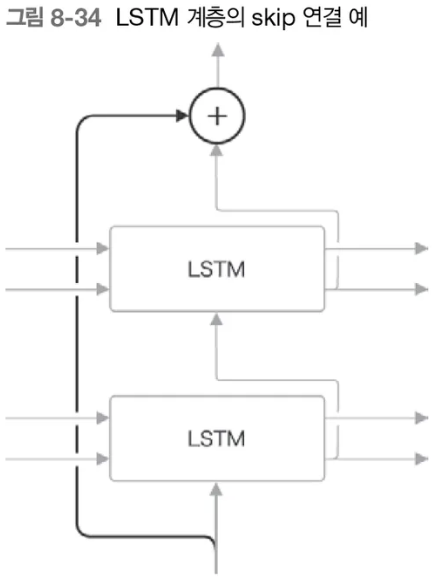
층을 깊게 할 때 사용되는 중요한 기법 중 skip 연결(skip connection)을 사용할 수 있다(residual connection or short-cut)
위 그림에서 보듯, skip 연결은 ‘계층을 건너뛰는 연결’이다. skip 연결의 접속부에서는 2개의 출력이 ‘더해’진다. 이 덧셈이 핵심이다.
왜냐하면 덧셈은 역전파 시 기울기를 ‘그대로 흘려’ 보내므로, skip 연결이 기울기가 아무런 영향을 받지 않고 모든 계층으로 흘러갈 수 있기 때문에, 층이 깊어져도 기울기 소실 혹은 폭발이 일어나지 않고 전파되어 결과적으로 좋은 학습을 기대할 수 있다.
RNN 계층의 역전파에서는 시간 방향에서 기울기 소실 혹은 폭발이 일어날 수 있다. 기울기 소실에는 LSTM과 GRU 등의 ‘게이트가 달린 RNN’으로 대응하고, 기울기 폭발에는 ‘기울기 클리핑’으로 대응 할 수 있다. 한편, RNN의 깊이 방향 기울기 소실에는 여기서 설명한 skip 연결이 효과적이다.
어텐션 응용
Attention은 굉장히 범용적기 때문에 다양한 Application이 존재한다. 여기서는 3가지 연구를 소개한다.
사실 이 책이 나온지 너무 오래됐기 때문에 소개되는 대부분이 old한 application이긴 하다
구글 신경망 기계번역(GNMT)
기계번역의 역사는 규칙 기반 → 용례 기반 → 통계 기반 → 신경망 기반 으로 변천되어 왔다.
구글 번역은 2016년부터 신경망 번역을 사용하고 있다(Google’s neural machine translation system:Bridging the gap between human and machine translation, arXiv:1609.08144)
이번 장에서 구현한 어텐션을 갖춘 seq2seq와 유사하게 되어 있음을 알 수 있다. 멀티레이어 LSTM, 양방향 LSTM, skip-connection, GPU 분산학습 등이 추가되었다.
트랜스포머
RNN은 이전 시각에 계산한 결과를 이용하여 순서대로 계산하기 때문에 시간 방향으로의 병렬 계산은 (기본적으로) 불가능하다.
따라서 이러한 현상을 극복하기 위해 “Attention is all you need”라는 논문에서 트랜스포머 아키텍처가 제안되었다. (참고로 RNN 대신 CNN을 사용하여 seq2seq을 구현하여 병렬처리를 성공한 케이스도 있음)
트랜스포머는 어텐션으로 구성되는데, 그중 self-attention이라는 기술이 핵심이다.
Self-attention은 글자 그대로 ‘자신에 대한 주목’이다. 즉, 하나의 시계열 데이터를 대상으로 한 어텐션으로, ‘하나의 시계열 데이터내에서’ 각 원소가 다른 원소들과 어떻게 관련되는지를 살펴본다.
지금까지는 ‘번역’과 같이 2개의 시계열 데이터 사이의 대응 관계를 구해왔다. 이때 Time Attention 계층에는 [그림 8-37]의 오니쪽 처럼 서로 다른 두 시계열 데이터가 입력되고 서로 Attention을 구한다.
반면 Self-attention에서는 두 입력 선이 모두 하나의 데이터로 나온다 (Decoder 쪽의 Attention에서는 서로 다른 두 시계열 데이터간 Attention도 구한다)
트랜스포머의 구조는 다음과 같다.
트랜스포머에서는 RNN 대신 Attention을 사용한다. Feed Forward 계층은 은닉층이 1개이고 활성화 함수로 ReLU를 이용한 완전연결계층 신경망이다.
이 책에는 트랜스포머에 대한 설명이 한쪽뿐이라서, 시계열 병렬처리에 대한 내용이 없다. 트랜스포머에서는 시계열 병렬처리를 위해 Positional Embedding을 사용한다.
뉴럴 튜링 머신(NTM)
인간은 복잡한 문제를 풀 때 ‘종이’와 ‘펜’을 사용하는 일이 많다.
이처럼 외부의 ‘저장 장치’ 덕분에 해택을 보는 일이 많다. 신경망에서도 이와 같은 ‘외부 메모리’를 이용해 새로운 힘을 부여할 수 있다.
어텐션을 갖춘 seq2seq에서는 Encoder가 입력 문장을 인코딩하고 Decoder가 이를 이용한다.
즉, Encoder가 필요한 정보를 메모리에 쓰면 Decoder가 그 메모리에서 필요한 정보를 적절히 참조한다고 해석 할 수 있다.
이렇게 생각하면, 컴퓨터의 메모리 조작을 신경망에서도 재현이 가능하다. 바로 생각할 수 있는 방법은 RNN의 외부에 정보 저장용 메모리 기능을 배치하고, 어텐션을 이용하여 그 메모리로부터 필요한 정보를 읽거나 쓰는 방식이다.
이러한 연구중 유명한 연구가 뉴럴 튜링 머신(Neural Turing machine)이다.
딥마인드에서 연구했으며, 후에 DNC(Differentiable Neural Computers)라는 기법으로 개선한 논문이 네이처지에 실렸음. DNC는 NTM의 메모리 조작을 더욱 강화한 버전이라고 볼 수 있음
NTM의 계층 구성을 간단히 그리면 다음과 같다.
LSTM의 은닉 상태를 ‘Write Head’ 계층이 받아서 필요한 정보를 메모리에 쓴다.
‘Read Head’ 계층이 메모리로부터 중요한 정보를 읽어 들여 다음 시각의 LSTM 계층으로 전달한다.
NTM은 컴퓨터의 메모리 조작을 모방하기 위해 2개의 어텐션을 사용한다. ‘컨텐츠 기반 어텐션’과 ‘위치 기반 어텐션’이다
‘컨텐츠 기반 어텐션’은 지금까지 본 어텐션과 같고, 입력으로 주어진 어느 벡터(query)와 비슷한 벡터를 메모리로부터 찾아내는 용도로 이용된다 (Self-attention의 query랑 비슷한데??)
‘위치 기반 어텐션’은 이전 시각에서 주목한 메모리의 위치(=메모리의 각 위치에 대한 가중치)를 기준으로 그 전후로 이동(시프트)하는 용도로 사용된다. 이 기술은 1차원의 합성곱 연산으로 구현된다. 메모리 위치를 시프트하는 이 기능을 사용하면 메모리 위치를 하나씩 옮겨가며 읽어 나가는 컴퓨터 특유의 움직임을 쉽게 재현 할 수 있다.
이러한 NTM은 특히 긴 시계열을 기억하는 문제와 정렬(=수들을 크기 순으로 나열) 등의 문제를 해결하고 있다.
또한 NTM은 외부 메모리를 사용함으로써 알고리즘을 학습하는 능력을 얻는다.
정리
번역이나 음성 인식 등, 한 시계열 데이터를 다른 시계열 데이터로 변환하는 작업에서는 시계열 데이터 사이의 대응 관계가 존재하는 경우가 많다.
어텐션은 두 시계열 데이터 사이의 대응 관계를 데이터로부터 학습한다.
어텐션에서는 (하나의 방법으로서) 벡터의 내적을 사용해 벡터 사이의 유사도를 구하고, 그 유사도를 이용한 가중합 벡터가 어텐션의 출력이 된다.
어텐션에서 사용하는 연산은 미분 가능하기 때문에 오차역전파법으로 학습할 수 있다.
어텐션이 산출하는 가중치(확률)을 시각화하면 입출력의 대응 관계를 볼 수 있다.
외부 메모리를 활용한 신경망 확장 연구 예에서는 메모리를 읽고 쓰는 데 어텐션을 사용했다.