

Intro
- 지금까지 설명한 RNN, LSTM으로 재밌는 애플리케이션인 ‘문장 생성’을 수행하는 방법을 배운다.
- 또한 seq2seq라는 새로운 구조의 신경망도 소개한다. 이 seq2seq2는 기계 번역, 챗봇, 메일 자동 답신 등 다양하게 응용될 수 있다.
언어 모델을 사용한 문장 생성
RNN을 사용한 문장 생성의 순서
- 언어 모델은 지금까지 주어진 단어들에서 다음에 출현할 단어의 확률 분포를 출력한다.
- 출력된 확률 분포에서, 가장 확률이 높은 단어를 선택할 수 있다. 이것이 “deterministic(결정적)” 방법이다. 이 경우, 확률이 적은 단어는 절대 생성 될 수 없다.
- 반면, 분포에서 Probabilistic(확률적) 으로 선택할 수 있다. 이 경우, 확률이 낮은 단어도 간혹 선택 될 수 있다.

- 위 작업을 원하는 만큼 혹은 <eos> 같은 종결 기호를 만날 때까지 계속 한다면 새로운 문장을 생성 할 수 있다.
seq2seq
- 대화, 음성, 동영상 등의 데이터는 모두 시계열 데이터이다.
- 이런 입력 시계열 데이터를 출력 시계열 데이터로 변환하는 모델을 알아보자.
- 여기서는 2개의 RNN을 사용하는 seq2seq(sequence to sequence)라는 방법을 살펴보자.
seq2seq의 원리
- seq2seq를 Encoder-Decoder 모델이라고도 한다.(seq2seq를 decoder only로 구현도 가능하다.)
- Encoder는 입력 데이터를 인코딩(부호화) 하고, Decoder는 인코딩된 데이터를 디코딩(복호화) 한다.
Encoding이란 정보를 어떤 규칙에 따라 변환하는 것이다. 문자 코드를 예로 들면 ‘A’라는 문자를 ‘1000001’이라는 이진수로 변환하는 식이다. 한편, 디코딩이란 인코딩된 정보를 원래의 정보로 되돌리는 것이다. 문자 코드를 예로 들면 ‘1000001’이라는 비트 패턴을 ‘A’라는 문자로 변환하는 일이 디코딩이다.
- seq2seq의 구조를 번역을 예로 들면 다음과 같다.

- 위 그림에서처럼 Encoder가 “나는 고양이로소이다”라는 입력 문장(source)을 인코딩하고, 그 인코딩된 정보를 Decoder에게 전달하면 Decoder가 출력 문장(target)인 “I am a cat”을 생성한다.
- 즉, Seq2Seq 구조에서는 Encoder와 Decoder가 협력하여 시계열 데이터를 다른 시계열 데이터로 변환한다.
- Encoder의 계층은 다음과 같이 생겼다.

- 위처럼 인코더는 시계열 데이터를 \(\textbf{h}\)라는 은닉 상태 벡터로 변환(인코딩)한다. LSTM 혹은 RNN, GRU, Transformer 구조 등 어떤 것이든 가능하다.
- 즉, 입력 문장이 고정 길이 벡터 \(\textbf{h}\)로 변환된 것
- Decoder의 계층은 다음과 같이 생겼다.

- 위 그림과 같이 Decoder는 Encoder와 구조가 동일하다.
- 다만, 인코더에서 넘어온 \(\textbf{h}\)를 입력으로 입력받는다. (인코더에서는 아무것도 입력받지 않았음)
- 디코더에서 받은 <eos>는 인코더 입장에서는 입력 문장의 마지막을 뜻하고, 디코더 입장에서는 출력 문장의 시작을 의미한다(<bos> 즉, begin of sequence 로 쓰는 경우가 더 많음)
- 인코더와 디코더를 연결한 계층 구조는 다음과 같다.

- LSTM 계층의 은닉 상태가 Encoder와 Decoder를 이어주는 ‘가교’가 된다.
- 순전파 때는 Encoder에서 인코딩된 정보가 LSTM 계층의 은닉 상태를 통해 Decoder로 전해진다.
- 역전파 때는 이 은닉 상태를 통해 기울기가 Decoder로부터 Encoder로 전해진다.
시계열 데이터 변환용 장난감 문제
- seq2seq 구조를 통해 ‘더하기’ 문제를 풀어보자
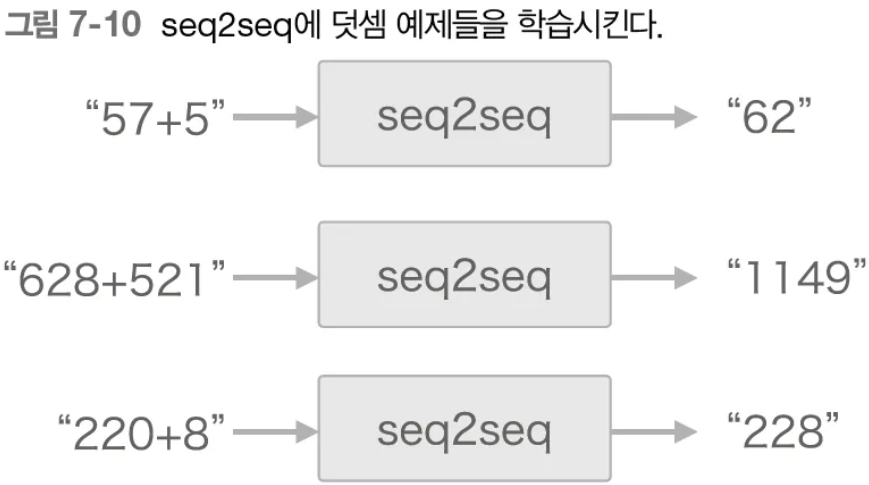
- 일반적으로 번역이나, 요약 등의 예시로 설명하는데 더하기로 seq2seq을 설명하는 책은 처음본다.. 좋은 시도 같다..
가변 길이 시계열 데이터
- 여러 ‘덧셈’ 문제를 미니배치로 처리하기 위해서는 각 미니배치 별로 시계열 길이가 다르다는 점을 주의해야 한다.
- 가변 길이 처리를 위한 패딩 작업
- 가변 길이 시계열 데이터를 처리하는 가장 쉬운 방법은 패딩(padding)을 사용하는 것이다. 패딩이란 원래의 데이터에 의미 없는 데이터를 채워 모든 데이터의 길이를 균일하게 맞추는 기법이다.
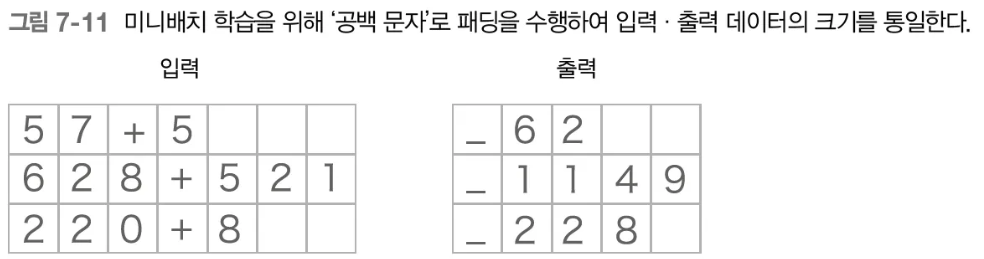
- 이번 문제에서는 0~999 사이의 숫자 2개만 더해보자. 그러면 ‘+’ 글자까지 포함하여 최대 7 문자까지 입력 된다. 출력은 최대 4문자이다.
- 밑줄(_)은 입력과 출력을 구분하기 위한 구분자이며, 디코더에게 정답을 생성하라고 알리는 신호가 된다.
- 이처럼 패딩을 적용하는 경우, 패딩에 대한 Loss는 포함하지 않도록 추가 작업이 필요하다(softmax with loss 계층에 ‘마스크’ 기능 추가).
- 또한 Encoder에 입력된 데이터가 패딩이라면 이전 시각의 입력을 그대로 출력하도록 처리할 수 있다. 이렇게 하면 마치 처음부터 패딩이 존재하지 않았던 것처럼 인코딩 할 수 있다.
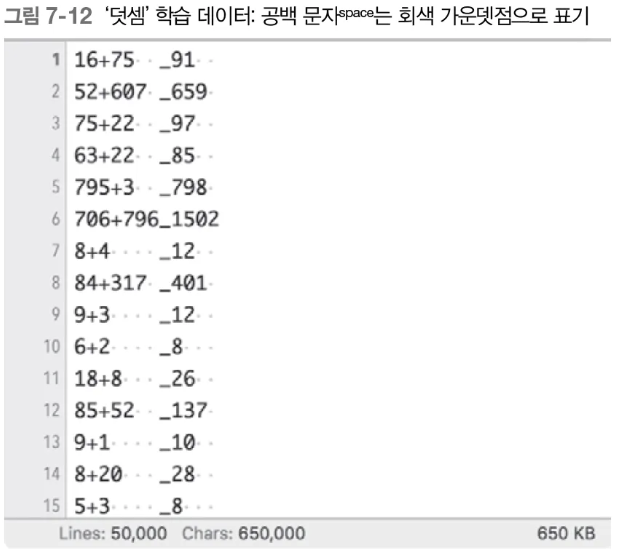
덧셈 데이터셋
- 덧셈 데이터셋은 다음과 같다(케라스 참조)
seq2seq 구현
Encoder 클래스

- Embedding 계층에서는 문자를 문자 벡터로 변환하여 LSTM 계층으로 보낸다.
- LSTM에서는 오른쪽으로는 은닉 상태와 셀 정보를 출력하고 위쪽으로는 은닉 상태만 출력한다. 위의 구성에서는 멀티레이어 LSTM이 아니기 때문에 이 정보는 폐기된다.
- 하나의 시점으로 표현하면 다음과 같음

Decoder 클래스

- Decoder는 Encoder의 \(\textbf{h}\)를 받아, 정답을 출력한다.
- Decoder에서도 Encoder와 마찬가지로 LSTM을 사용한다.

문장을 생성할 때, 학습 시는 정답을 알고 있기 때문에 시계열 방향의 데이터를 한번에 넣어줄 수 있지만, 추론 시에는 최초 시작을 알리는 문자 외에는 미리 줄 수 없다. 추론을 한글자씩 하면서 넣어준다.
- 덧셈 문제이기 때문에 Deterministic하게 정답을 생성해 보자.

- argmax 노드는 최대값을 가진 원소 인덱스를 선택하는 노드이다.
seq2seq 개선
입력 데이터 반전(Reverse)

- 위 그림처럼 입력 숫자의 순서만 바꿔도 성능이 향상되는 것으로 나온다. 왜 그럴까?
- (저자)직관적으로 보면 기울기 전파가 원활해지기 때문이라고 생각
- 예를 들어, “I am a cat”을 “나는 고양이로소이다”로 변환하는 문제를 고려해보면,

- “I” 라는 단어를 맞추기 위해서는 “나”라는 글자에 대한 정보가 필요하고 틀렸다면 loss에 대한 gradient도 전달이 되야 하는데, 기존 시퀀스에서는 4단계(는, 고양이, 로소, 이다)를 거쳐서 전달이 되지만 반전 시퀀스에서는 바로 옆에 있으니 바로 전달이 가능하다.
엿보기(Peeky)
- Encoder에서 넘어온 \(\textbf{h}\)에는 문제를 해결하기 위한 귀중한 정보가 담겨있다. 따라서 Decoder의 다른 계층(입력 레이어, Affine 레이어)에도 이 정보를 넣어줄 수 있다.(마치 Residual Connection 같군)

- 확대하면 다음과 같다. Affine 계층에 2개의 벡터를 concat 해서 입력으로 넣을 수 있다. (그럼 Affine 계층의 dimension이 H에서 2H로 커져야함)

- reverse + peeky 트릭을 합친 결과(정답률)

(생각보다 수치가 너무 높다;; LSTM만으로도 세자리수 덧셈은 쉽게 할 수 있는건가?)
정리
- RNN을 이용한 언어 모델은 새로운 문장을 생성할 수 있다.
- 문장을 생성할 때는 하나의 단어(혹은 문자)를 주고 모델의 출력(확률분포)에서 샘플링하는 과정을 반복한다.
- RNN을 2개 조합함으로써 시계열 데이터를 다른 시계열 데이터로 변환할 수 있다.
- seq2seq는 Encoder가 출발어 입력문을 인코딩하고, 인코딩된 정보를 Decoder가 받아 디코딩하여 도착어 출력문을 얻는다.
- 입력문을 반전시키는 기법(Reverse), 또는 인코딩된 정보를 Decoder의 여러 계층에 전달하는 기법(Peeky)은 seq2seq의 정확도 향상에 효과적이다.
- 기계번역, 챗봇, 이미지 캡셔닝 등 seq2seq는 다양한 애플리케이션에 이용할 수 있다.
'인공지능 > [책] 밑바닥부터 시작하는 딥러닝2' 카테고리의 다른 글
| [책 요약] 밑바닥부터 시작하는 딥러닝2-Chapter 8. 어텐션 (0) | 2024.11.12 |
|---|---|
| [책 요약] 밑바닥부터 시작하는 딥러닝2-Chapter 6. LSTM(게이트가 추가된 RNN) (0) | 2024.11.12 |
| [책 요약] 밑바닥부터 시작하는 딥러닝2-Chapter 5. 순환 신경망(RNN) (0) | 2024.11.11 |
| [책 요약] 밑바닥부터 시작하는 딥러닝2-Chapter 4. word2vec 속도 개선 (0) | 2024.11.11 |
| [책 요약] 밑바닥부터 시작하는 딥러닝2-Chapter 3. word2vec (1) | 2024.11.11 |