

추론 기반 기법과 신경망
- 앞장에서 배운 PPMI처럼 단어의 등장 횟수를 세는 방식은 통계기반 방법이라면, word2vec은 데이터를 통해 학습하고 그 결과를 토대로 추론 하는 추론 기반 기법이다.
통계 기반 기법의 문제점
- 단어의 동시발생 행렬을 만들고 그 행렬에 SVD를 적용하여 밀집벡터를 얻을 수 있다.
- 하지만 현업에서 다루는 말뭉치의 어휘 수는 어마어마하다. 100만개라고 해도 행렬의 차원이 ‘100만 X 100만’이 되므로 이러한 행렬을 실제로 다루는 것은 현실적이지 않다.
SVD를 n x n 행렬에 적용하는 비용은 \(O(n^3)\)이다.
- 통계 기반 기법은 말뭉치 전체의 통계를 이용해 단 1회의 처리 만에 분산 표현을 얻는다.(배치)
- 한편, 추론 기법에서는 미니배치로 학습하는 것이 일반적이다.(미니배치)
추론 기반 기법 개요
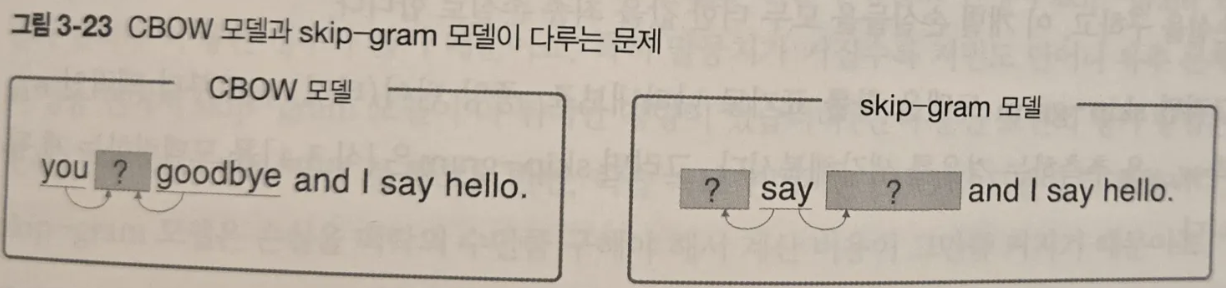
- 추론 기반 기법에서는 당연히 ‘추론’이 주된 작업이다. 추론이란 맥락이 주어졌을 때 “?”에 무슨 단어가 들어갈지를 추측하는 작업이다
you ? goodbye and I say hello
- ‘모델 관점’에서 보면 추론 문제는 다음과 같다.

- 추론 기반 기법에서는 모델(신경망)에 맥락을 입력 받아 각 단어의 출현 확률을 출력한다.
- 이러한 틀 안에서 말뭉치를 사용해 모델이 올바른 추측을 내놓도록 학습시킨다.
- 추론 기반 기법도 통계 기반 기법처럼 분포 가설에 기초한다.
신경망에서의 단어 처리
- 신경망에 단어를 그대로 입력할 수 없기에 ‘고정 길이의 벡터’로 변환해야 한다.
- 이때 사용하는 대표적인 방법이 one-hot 벡터이다. 벡터의 하나만 1이고 나머지는 모두 0인 벡터를 말한다.

- 원핫 벡터를 만들기 위해선 총 어휘 수만큼의 원소를 갖는 벡터를 준비하고 인덱스를 통해 1, 0을 표시한다.
- 이처럼 단어를 고정 길이 벡터로 변환하면 우리 신경망의 입력층은 다음처럼 뉴런의 수를 고정할 수 있다.

- 입력층의 뉴런은 총 7개이며, 이 7개의 뉴런은 차례로 7개의 단어들에 대응한다.
- 즉, you가 신경망에 입력 될 때는 [1, 0, …0] 이 입력되고, say가 입력 될 때는 [0, 1, 0, …, 0]이 입력된다. (아직 you say hello 처럼 여러 단어가 한번에 들어가는 설명은 나오지 않음)
- 단어의 갯수가 7개이고 출력이 3인 신경망을 표현한 그림(편향은 생략)

- 위 그림에서 헷갈리면 안되는게, 이것은 단어 임베딩이므로 ‘you say good bye …’ 라는 문장이 한번에 들어가는게 아니라 저 중에서 1개의 단어만 들어가는 것임에 유의해야한다.
- 결국 입력 값이 벡터이지만 하나의 원소만 1이라는건 W 행렬에서 한개의 행만 뽑아내는 것과 마찬가지의 결과가 된다.

- 내 생각
- 여기까지만 봐도 어떤 하나의 단어가 one-hot vector로 표현이 되고 다시 W의 행에 해당하는 벡터로 치환됨으로써 단어가 벡터로 표현되는 것을 볼 수 있다.
- 단어 → one-hot → W의 1개의 Row
- 요부분에 대해서 이런 추가 설명이 더 들어갔으면 어땠을까 하는 생각이 든다. 처음 보는 사람은 살짝 이해가 안됬을 것 같다.
단순한 word2vec
- word2vec이라는 용어는 원래 프로그램이나 도구를 가리키는데 사용되었으나 이 용어가 유명해지면서, 문맥에 따라서는 신경망 모델을 가리키는 경우도 많이 볼 수 있다. CBOW 모델과 skip-gram 모델은 word2vec에서 사용되는 모델이다.
CBOW 모델의 추론 처리
- CBOW 모델은 맥락으로부터 타깃을 추측하는 용도의 신경망이다.
- CBOW 모델의 입력은 맥락이다. 맥락은 “you”와 “goodbye”같은 단어들의 목록이다.
- CBOW의 신경망 구조를 설명하기에 앞서, CBOW는 앞뒤 단어가 주어지고 가운데 단어를 맞추는 거라고 설명해야 하지 않나?? 너무 갑자기 신경망으로 들어가는데..
- CBOW 모델의 신경망 구조

- 입력층이 2개(입력 값이 2개)이고 은닉층, 출력층이 있음
- 입력층이 2개인 이유는 맥락으로 고려할 단어를 2개로 정했기 때문. N개면 N개의 입력층이 필요
- 두 입력층에서 은닉층으로의 변환은 똑같은 완전연결 계층($W_{in}$)이 처리
- 은닉층에서 출력층 뉴런으로의 변환은 다른 완전연결계층($W_{out}$)이 처리
- 은닉층의 뉴런은 입력층의 값들을 평균한다.
- 출력층의 뉴런은 전체 vocab 갯수(여기선 7개)만큼이 필요하다. 출력층 뉴런은 각 단어의 ‘점수’를 뜻하며, 이 점수에 softmax를 취하면 등장 확률이 된다.
- 입력된 단어는 입력층의 \(W_{in}\)의 각 행에 의해서 결정되므로 행의 값이 단어의 분산 행렬 그 자체이다

은닉층의 뉴런 수를 입력층의 뉴런 수보다 적게 하는 것이 중요한 핵심이다. 이렇게 해야 은닉층에는 단어 예측에 필요한 정보를 ‘간결하게’ 담게 되며, 결과적으로 밀집 벡터 표현을 얻을 수 있다. 이때 그 은닉층의 정보는 우리 인간은 이해할 수 없는 코드로 쓰여 있다. 바로 ‘인코딩’에 해당한다. 한편 은닉층의 정보로부터 원하는 결과를 얻는 작업은 ‘디코딩’이라고 한다. 디코딩이란 인코딩된 정보를 우리 인간이 이할 수 있는 표현으로 복원하는 작업이다(사실 엄밀한 표현은 아님. 디코딩을 해도 벡터로 표현되기도 하므로).
- 계층 관점에서 본 CBOW 모델의 신경망 구조(평균을 계산하는 은닉층이 +, x 로 표시됨)

CBOW 모델의 학습

- CBOW 모델의 학습에서는 올바른 예측을 할 수 있도록 가중치를 조정하는 일을 한다.
- 그 결과로 가중치 \(W_{in}\), \(W_{out}\)에 단어의 출현 패턴을 파악한 벡터가 학습된다.
- 이 모델은 다중 클래스 분류를 수행하는 신경망이다. 따라서 소프트맥스와 교차 엔트로피 오차만 이용하면 된다.
- CBOW 모델의 학습 시 신경망 구성

word2vec의 가중치와 분산 표현
- word2vec에서 사용되는 신경망에는 2가지 가중치가 있다. \(W_{in}, W_{out}\)
- 그리고 이것들이 단어의 의미가 인코딩되어 저장된 벡터라고 생각할 수 있다.

- 최종적으로 어떤 벡터를 단어의 분산 표현으로 사용하면 좋을까?
- \(W_{in}\)
- \(W_{out}\)
- 둘 다
- word2vec(특히 skip-gram)에서는 \(W_{in}\)만 사용하는 것이 보편적이다.
- GloVe에서는 두 가중치를 더했을 때 더 좋은 결과를 얻었다.
학습 데이터 준비
- 학습에 쓰일 예시로 “You say goodbye and I say hello”라는 한 문장을 이용해보자.
맥락과 타깃
- word2vec에서 이용하는 신경망의 입력은 ‘맥락’이다. 그리고 그 정답 레이블은 맥락에 둘러싸인 중앙의 단어, 즉 ‘타깃’이다.
- 다시 말해, 우리가 해야 할 일은 신경망에 ‘맥락’을 입력했을 때 ‘타깃’이 출현할 확률을 높이는 것이다.
- 쉽게 말해, 양 옆 단어를 주고 가운데 단어를 맞추는 거
- 맥락과 타깃은 다음과 같이 만들 수 있다.

- 말뭉치내에서 모든 단어에 대해서 맥락과 타깃을 만들어 낸다(양 끝 단어 제외)
- 여기서는 맥락을 양 옆 2개의 단어로 설정함(더 길게 만들수도 있음, contexts window size=1)

원핫 표현으로 변환
- 신경망에 입력을 위해 원핫벡터로 변환해보자.

CBOW 모델의 구현

# 순전파 함수
def forward(self, contexts, target):
h0 = self.in_layer0.forward(contexts[:, 0])
h1 = self.in_layer1.forward(contexts[:, 1])
h = (h0+h1) * 0.5
score = self.out_layer.forward(h)
loss = self.loss_layer.forward(score, target)
return loss- contexts는 3차원 넘파이 배열이며, (batch, contexts_length, onehot_length)가 됨
- CBOW의 역전파 예시

- softmax with loss 계층의 역전파 출력이 \(\textbf{ds}\)
word2vec 보충
CBOW 모델과 확률
- 사후 확률은 \(P(A|B)\)로 쓴다. 이는 말 그대로 ‘사건’이 일어난 후의 확률이다. ‘B’라는 정보가 주어졌을 때 A가 일어날 확률’이라고도 해석 할 수 있다.
- CBOW 모델을 확률 표기법으로 표기해보자. CBOW 모델이 하는 일은 맥락을 주면 타깃 단어가 출현할 확률을 출력하는 것이다.

- 위의 상황을 수식으로 나타내면 다음과 같다
$$P(w_t|w_{t-1}, w_{t+1})$$
- 위 식을 이용하면 CBOW 모델의 손실 함수도 간결히 표현 가능하다.
- cross entropy loss 식은 \(L=-\sum{t_k log \space y_k}\) 이고, \(y_k\)는 k 번째에 해당하는 사건이 일어날 확률이다. \(t_k\)는 정답 레이블이며, 원핫 벡터로 표현된다.
- 따라서,
$$L = -log P(w_t|w_{t-1}, w_{t+1})$$ - CBOW 모델의 손실 함수는 단순히 위 식에 log와 마이너스를 붙인 것이며 이를 음의 로그 가능도(negative log likelihood) 라고 한다.
- 모든 말뭉치 전체로 Loss를 확장하면,
$$L = -\frac{1}{T}\sum_{t=1}^T{log P(w_t|w_{t-1}, w_{t+1})}$$
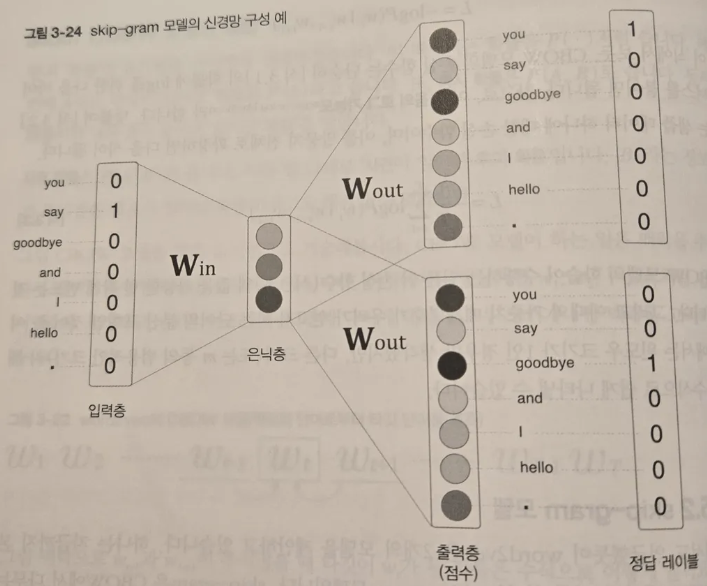
skip-gram 모델
- skip-gram 모델은 중앙의 단어로부터 주변의 여러 단어를 추측한다.
- skip-gram 모델의 신경망 구성
- skip-gram 모델을 확률로 표현하면 다음과 같다.
$$P(w_{t-1}, w_{t+1}|w_t)$$ - skip-gram에서 맥락의 단어들 사이에 관련성이 없다고 가정하면 다음과 같이 분해 가능(근데 독립이 아닐텐데??)
$$P(w_{t-1}, w_{t+1}|w_t) = P(w_{t-1}|w_t)P(w_{t+1}|w_t)$$ - 이어서 이를 교차 엔트로피 오차에 적용하여 skip-gram 모델의 손실 함수를 유도할 수 있다.
$$\begin{align}L &= -logP(w_{t_1}, w_{t+1}|w_t)\\ &= -logP(w_{t_1}|w_t)P(w_{t+1}|w_t)\\
&= -(logP(w_{t_1}|w_t)+logP(w_{t+1}|w_t))
\end{align}$$ - skip-gram vs CBOW
- 단어 분산 표현의 정밀도 면에서 skip-gram이 더 좋은 경우가 많다.
- 특히 말뭉치가 커질수록 저빈도 단어나 유추 문제의 성능 면에서 skip-gram이 더 뛰어난 경향을 보인다. skip-gram은 하나의 단어로부터 주변 단어를 예측해야 하므로 CBOW 문제보다 더 어려운 문제를 푼다고 할 수 있기 때문이다(그러니까, 저빈도 단어처럼 데이터가 몇개 없어서 학습이 몇 번 되지 않는 단어는 그 몇번 안되는 기회를 잘 살려야하기 때문에 더 어려운 문제를 푸는 skip-gram이 더 낫다고 봐야 할까)
- 반면 학습 속도는 CBOW 모델이 빠르다.
통계 기반 vs. 추론 기반
- 통계 기반은 말뭉치의 전체 통계로부터 1회 학습하여 단어의 분산 표현을 얻는다.
- 추론 기반은 미니배치 학습을 통해 단어의 분산 표현을 얻는다.
- 어휘에 추가할 새 단어가 생겨서 단어의 분산표현을 갱신해야 하는 상황을 생각해보면
- 통계 기반 기법에서는 계산을 처음부터 다시 해야 한다. 동시발생 행렬을 다시 만들고 SVD를 수행하는 작업을 다시 해야 한다.
- 반면, 추론 기반 기법은 지금까지 학습한 가중치를 초깃값으로 사용하고 새로운 가중치를 추가하여 학습하면 된다.
- 이런 점에서 추론 기반 기법이 우세하다.
- 단어의 분산 표현의 성격이나 정밀도 면에서는 어떨까?
- 통계 기반 기법에서는 주로 단어의 유사성이 인코딩 된다.
- 추론 기반 기법에서는 유사성은 물론 단어 사이의 패턴까지도 파악이 된다. (king - man + woman = queen이 되는 유명한 예시)
- 그러나 실제로 단어의 유사성을 정량 평가해본 결과, 의외로 추론 기반과 통계 기반 기업의 우열을 가릴 수 없었다고 한다(Improving distributional similarity with lessons learned from word embeddings, 2015)
- 또한, 추론 기반 기법과 통계 기반 기법은 서로 관련되어 있다고 함. 구체적으로 skip-gram과 네거티브 샘플링을 이용한 모델은 모두 말뭉치 전체의 동시발생 행렬(실제로는 살짝 수정한 행렬)에 특수한 행렬 분해를 적용한 것과 같다.
- SVD하고 신경망 학습이 유사하다니.. 당연하면서도 신기하게 느껴진다
- 이후 추론 기법과 통계 기반 기법을 융합한 GloVe 기법이 등장함. GloVe의 기본 아이디어는 말뭉치 전체의 통계 정보를 손실 함수에 도입해 미니배치 학습을 하는 것임.
정리
- 추론 기반 기법은 추측하는 것이 목적이며, 그 부산물로 단어의 분산 표현을 얻을 수 있다.
- word2vec은 추론 기반 기법이며, 단순한 2층 신경망이다.
- word2vec은 skip-gram 모델과 CBOW 모델을 제공한다
- CBOW 모델은 여러 단어(맥락)로부터 하나의 단어(타깃)을 추측한다.
- 반대로 skip-gram 모델은 하나의 단어(타깃)로부터 다수의 단어(맥락)을 추측한다.
- word2vec은 가중치를 다시 학습할 수 있으므로, 단어의 분산 표현 갱신이나 새로운 단어 추가를 효율적으로 수행할 수 있다.
'인공지능 > [책] 밑바닥부터 시작하는 딥러닝2' 카테고리의 다른 글
| [책 요약] 밑바닥부터 시작하는 딥러닝2-Chapter 7. RNN을 사용한 문장 생성 (0) | 2024.11.12 |
|---|---|
| [책 요약] 밑바닥부터 시작하는 딥러닝2-Chapter 6. LSTM(게이트가 추가된 RNN) (0) | 2024.11.12 |
| [책 요약] 밑바닥부터 시작하는 딥러닝2-Chapter 5. 순환 신경망(RNN) (0) | 2024.11.11 |
| [책 요약] 밑바닥부터 시작하는 딥러닝2-Chapter 4. word2vec 속도 개선 (0) | 2024.11.11 |
| [책 요약] 밑바닥부터 시작하는 딥러닝2-Chapter 2. 자연어와 단어의 분산 표현 (0) | 2024.11.11 |