

Ch 1. 학습목표
- 기계학습(머신러닝) 주요 알고리즘의 이해
- 머신러닝 교차검증의 이해
- 머신러닝 주요 모델 구현 방법 습득
- 예측 모델링에서의 주의사항 습득
- 머신러닝 결과물을 전달하는 방법 습득
Ch 2. 예측 모델링 시작하기

- 지도학습(Supervised Learning): 정답(label)이 있는 훈련 데이터(training data)로부터 학습
- 대부분의 머신러닝 방법
- 예: Naive-Baysian Classifier, Random Forest Classifier
- 비지도학습(Unsupervised Learning): 정답(label) 없이 훈련 데이터(training data)를 학습
- 대부분의 거리 기반 알고리즘
- 예: k-평균 군집화(k-Means Clustering), 주성분분석(Principal Component Analysis)
- 준지도학습(Semi-supervised Learning): 정답(label)이 있는 훈련 데이터와 없는 훈련 데이터를 학습
- 정답(label)이 있는 X와 y의 분포와 레이블이 없는 X와 y의 분포가 유사하다는 가정
- 참고: 강화학습, 전이학습
선형 예측 모형의 기본 개념과 원리(1): 회귀, Ridge, Lasso
- 회귀
- 선형회귀: 최소제곱 추정(Least Squares Estimation)
- 로지스틱: 최대우도 추정(Maximum Likelihood Estimation)
- BLUE(Best Linear Unbiased Estimator) → ordinary least squares (OLS) estimator
- 가정 1: 종속변수는 독립변수의 계수와 선형관계이며 회귀모형은 꼭 필요한 독립변수를 포함하고 있다. (선형성)
- 가정 2: 독립변수 사이에 선형관계가 없다
- 가정 3: 독립변수는 오차항과 상관이 없다
- 가정 4: 오차항은 서로 독립적이며 서로 연관되어 있지 않다
- 가정 5: 오차항의 평균은 0이다
- 가정 6: 오차항의 분산은 일정하다
- Regularization (정규화)의 개념 -> 딥러닝에서 다시 다룹니다!
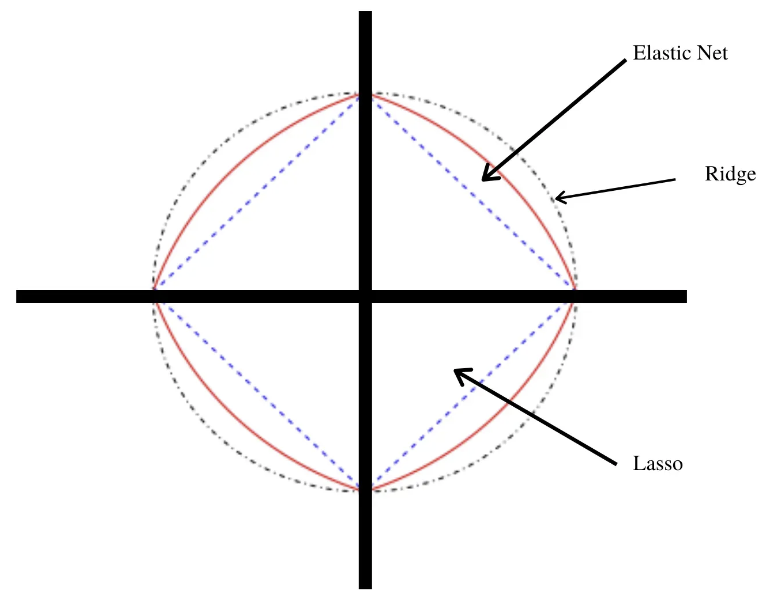
- Ridge (능형회귀)
- Lasso (Least absolute shrinkage and selection operator) by Travor Hastie

- Elestic-Net(Lasso와 Ridge의 하이브리드)
선형 예측 모형의 기본 개념과 원리(2): LPM, 로지스틱, SVM
- Linear Probability Model (선형확률모델): Linear Regression으로 확률 자체를 예측, 확률이 0보다 작아지거나 1보다 커질 수 있는 문제가 있음
- Logistic Regression (로지스틱 회귀)
- Logit의 개념
- Softmax Classifer -> 딥러닝에서 다시 다룹니다!
- 평가지표: Pseudo R^2
- Support Vector Machines (SVM)
- 장점: 다차원 데이터에서도 유연하게 최적해를 구할 수 있음
- 단점: 오버피팅 발생
선형 예측 모형의 기본 개념과 원리(3): 추정방법과 평가지표
- 추정(estimation)
- MLE
- Penalized MLE
회귀 문제의 평가지표
- 설명력(R^2, R squared) = (1 - RSS)/TSS

- \(TSS=\sum{(y-\bar{y})^2}\), y와 y의 평균의 차이
- \(RSS=\sum{(y-\hat{y})^2}\), y와 y의 예측의 차이
- 전체에서 설명이 안 된 부분을 뺀 수치
- 상관계수의 제곱
- 상관계수의 제곱이 작으면 설명이 잘 안된다고 생각할 수 있으니..
분류 문제의 평가지표
- Accuracy
- Precision
- Recall
- F1 -> 머신러닝에서 제일 중요한 지표!
트리 기반 모형의 기본 개념과 원리(1): Decision Tree
- 의사결정 나무
- 프루닝(Pruning)
트리 기반 모형의 기본 개념과 원리(2): 앙상블
- 약한 학습기(Weak Learners)도 모이면 강력해진다!
- 어떻게 모을까? --> 평균, 가중치 등
- 세부방식에 따라 알고리즘의 종류가 달라짐
- 현대 머신러닝의 기본 방식이며, 우리가 사용할 거의 모든 알고리즘은 앙상블 학습기라고 생각하시면 됩니다.
- 딥러닝도 결국 앙상블 학습기입니다
- 참고: 스태킹 앙상블(stacking ensemble): Kaggle 등에서 점수를 조금이라도 더 높이고자 할 때 사용하는 방법
- 앙상블: 알고리즘이 분류를 할 때, 적합(fitting)을 하고 추정하는 학습방법(weak learner들의 종합)
- 앙상블: 여러 세부 알고리즘을 가지고 하나의 "가장 좋은" 알고리즘을 선택하는 학습(meta learning) 방법
- stacking + ensemble
트리 기반 모형의 기본 개념과 원리(3): Bagging
- Bagging은 샘플을 여러 번 뽑아 각 모델을 학습시켜 결과를 집계(Aggregating) 하는 방법입니다.

트리 기반 모형의 기본 개념과 원리(4): Boosting
- https://swalloow.github.io/bagging-boosting/
- Bagging이 일반적인 모델을 만드는데 집중되어있다면, Boosting은 맞추기 어려운 문제를 맞추는데 초점이 맞춰져 있습니다.
- Boosting도 Bagging과 동일하게 복원 랜덤 샘플링을 하지만, 가중치를 부여한다는 차이점이 있습니다. Bagging이 병렬로 학습하는 반면, Boosting은 순차적으로 학습시킵니다. 학습이 끝나면 나온 결과에 따라 가중치가 재분배됩니다.
- 오답에 대해 높은 가중치를 부여하고, 정답에 대해 낮은 가중치를 부여하기 때문에 오답에 더욱 집중할 수 있게 되는 것 입니다. Boosting 기법의 경우, 정확도가 높게 나타납니다. 하지만, 그만큼 Outlier에 취약하기도 합니다.
- AdaBoost, XGBoost, GradientBoost 등 다양한 모델이 있습니다. 그 중에서도 XGBoost 모델은 강력한 성능을 보여줍니다. 최근 대부분의 Kaggle 대회 우승 알고리즘이기도 합니다.
- 부스팅은 여러 트리의 적합 결과를 합하는 앙상블 알고리즘의 하나로, 이 때 sequential의 개념이 추가되어 있습니다. 즉 연속적인 weak learner, 바로 직전 weak learner의 error를 반영한 현재 weak learner를 잡겠다는 것입니다. 이 아이디어는 Gradient Boosting Model(GBM)에서 loss를 계속 줄이는 방향으로 weak learner를 잡는다는 개념으로 확장됩니다.

- 부스팅 계열 모델은 Gradient Boosting Model(GradientBoostingClassifier), XGBoost, LightGBM (LGBMClassifier) 등이 있습니다.
트리 기반 모형의 기본 개념과 원리(5): 최신 동향
- [논문 pdf] LightGBM: A Highly Efficient Gradient Boosting Decision Tree, NeurIPS, 2017
- Light GBM이 빠른 이유는? 효과적으로 feature를 줄일 수 있음
- Light GBM의 장단점은? 속도는 빠르나 Accuracy는 비슷
- [논문 pdf] Towards Causal Representation Learning, 2021
- [백서 pdf] Practitioners Guide to MLOps: A framework for Continuous Delivery and Automation of Machine Learning
- (쉬운 버전) MLOps: 머신러닝의 지속적 배포 및 자동화 파이프라인
Ch 3. (실습) 머신러닝 예측 모델 구현하기
과제1: 소득구간 예측
데이터 소개
- US Census Bureau에서 수집하고 UCI에서 배포한 US Adult Income 데이터셋에 강사가 자체 제작한 모의 변수를 추가·수정한 데이터를 사용합니다.
- 첫번째로 사용할 데이터는 US Adult Income 데이터셋이며 분류할 타겟 레이블과 변수(피처)는 아래와 같습니다.
- age : 나이
- workclass: 직업구분
- education: 교육수준
- education.num: 교육수준(numerically coded)
- marital.status: 혼인상태
- occupation : 직업
- relationship: 가족관계
- race: 인종
- sex: 성별
- capital.gain: 자본이득
- capital.loss: 자본손실
- hours.per.week: 주당 근로시간
- income : 소득 구분
- 원 데이터 출처: https://archive.ics.uci.edu/ml/datasets/adult
- 실습 코드
scikit-learn에서 제공하는 피처 스케일러(scaler)
- StandardScaler: 기본 스케일, 각 피처의 평균을 0, 표준편차를 1로 변환

- RobustScaler: 위와 유사하지만 평균 대신 중간값(median)과 일분위, 삼분위값(quartile)을 사용하여 이상치 영향을 최소화
- MinMaxScaler: 모든 피처의 최대치와 최소치가 각각 1, 0이 되도록 스케일 조정
- Normalizer: 피처(컬럼)이 아니라 row마다 정규화되며, 유클리드 거리가 1이 되도록 데이터를 조정하여 빠르게 학습할 수 있게 함
- 스케일 조정을 하는 이유는 데이터의 값이 너무 크거나 작을 때 학습이 제대로 되지 않을 수도 있기 때문입니다. 또한 스케일의 영향이 절대적인 분류기(예: knn과 같은 거리기반 알고리즘)의 경우, 스케일 조정을 필수적으로 검토해야 합니다.
- 스케일 조정시 유의해야할 점은 원본 데이터의 의미를 잃어버릴 수 있다는 것입니다. 최종적으로 답을 구하는 것이 목적이 아니라 모델의 해석이나 향후 다른 데이터셋으로의 응용이 더 중요할 때 원 피처에 대한 설명력을 잃어버린다면 모델 개선이 어려울 수도 있습니다. 이 점을 함께 고려하시면 좋겠습니다.
- 반면 어떤 항목은 원본 데이터의 분포를 유지하는 것이 나을 수도 있습니다. 예를 들어, 데이터가 거의 한 곳에 집중되어 있는 feature를 표준화시켜 분포를 같게 만들었을 때, 작은 단위의 변화가 큰 차이를 나타내는 것처럼 학습될 수도 있습니다. 또한 스케일의 영향을 크게 받지 않는 분류기(예: 트리 기반 앙상블 알고리즘)를 사용할 경우에도 성능이 준수하게 나오거나 과대적합(overfitting)의 우려가 적다면 생략할 수도 있습니다.

Ch 4. (실습) 예측 결과 평가하기
성능 측정과 해석(1): Accuracy, Precision, Recall
- 정확도(Accuracy)
- 예측 결과와 실제값이 동일한 건수 / 전체 데이터 수
- 정밀도(Precision)
- 실제로 Positive인 데이터를 모델이 Positive라고 분류한 데이터의 비율
- TP / (FP + TP)
- 재현율(Recall)
- 실제값이 Positive인 대상중에 예측값과 실제값이 Positive로 일치한 데이터의 비율
- TP / (FN + TP)
- 민감도(Sensitivity) 또는 TPR(True Positive Rate)라고도 불린다
- scikit learn에서 accuracy_score, precision_score, recall_score 등을 통하여 구할 수 있다
성능 측정과 해석(2): F1, Confusion Matrix, AUC
- F1
- Precision과 Recall의 조화평균
- Confusion Matrix
- 오차행렬
- AUC (Area Under ROC Curve)
- 종합적 판단지표
- scikit learn에서 confusion_matrix, f1_score 등을 통하여 구할 수 있다

머신러닝 결과의 시각화(1)
- Logistic Regression 이진분류 모델의 회귀계수 시각화 하기

머신러닝 결과의 시각화(2)
(참고) 머신러닝 모델에서 변수의 영향력을 계산하는 방법
- 1) 회귀 모델의 회귀계수(Coefficients)
- X(피처)의 변량에 따라 y(타겟)의 변량이 어느 정도로 변하는지 수치화한 값
- 변수 영향력의 방향(긍정, 부정)을 알 수 있다는 장점
- 단점: 변수 스케일의 영향을 받기 때문에 스케일링 작업이 중요
- scikit-learn의 coef_ 메서드 사용
- 2) 트리 기반 모델의 MDI(Mean Decrease Impurity) 기반 중요도
- 해당 피처가 모델에 적용될 때 전체적으로 분류 결과의 불순도(impurity)를 얼마나 감소시키는지를 측정
- 불순도(impurity)의 측정 방법은 주로 entropy 혹은 Gini impurity로 계산
- 피처가 모델이 분류를 잘 하는데 중요하게 작용할 수록 값이 커지게 됨
- scikit-learn의 feature_importances_ 메서드 사용
- 3) 치환(Permutation) 기반 중요도
- 특정 피처의 값을 임의의 값으로 치환했을 떄 원래 데이터보다 예측 에러가 얼마나 더 커지는가를 측정
- 장점: 해석이 직관적이며, 계산에 시간이 오래 걸리지 않음
- 단점: 변수간 상호의존성 때문에 특정 피처의 영향력을 과대 혹은 과소추정할 수 있음
- scikit-learn의 permutation_importance 메서드 사용
- eli5의 PermutationImportance 메서드 사용
- 4) LGBM 모델의 분기 기반 중요도
- 기본값으로는 각 피처에서 결정을 내리기까지 분기(split)한 횟수를 나타냄
- 파라미터 설정을 바꾸면 분기에서 얻어낸 정보 이득(gain)의 총합을 나타낼 수 있음
- scikit-learn의 feature_importances_ 메서드 사용
- light gbm의 plot_importance 메서드 사용
- 5) XAI 커뮤니티에서 제안하는 게임이론 기반 Shapely 값
- 치환 피처 중요도(Permutation Importance)와 비슷하게 임의의 값으로 치환했을 때의 pay-off를 측정
- 장점: 변수간 상호의존성에 영향을 받지 않으며, 계산시마다 값이 달라지지 않음, 변수 영향력의 방향(긍정, 부정)을 알 수 있음
- 단점: 학습결과가 아니라 원 데이터에서 결정되기 때문에 아웃라이어에 약할 수 있음, 계산이 오래 걸림
- shap의 shap_values 메서드 사용
- 각 방법론은 장단점이 뚜렷하고 계산방식이 다르므로 머신러닝 모델 해석시 상황에 맞게 적용하는 것이 중요합니다.
Ch 5. (실습) 머신러닝 실전편
요약

'인공지능 > [강의] 딥러닝, 머신러닝을 활용한 시계열 데이터 분석' 카테고리의 다른 글
| AR, MA, ARMA, ARIMA 관련 기본 설명, 비트코인 예시 링크 (0) | 2024.11.13 |
|---|---|
| [강의 요약] 패캠 시계열 분석 - Part5. 딥러닝을 이용하여 정교하게 예측하기 (0) | 2024.11.13 |
| [강의 요약] 패캠 시계열 분석 - Part4. 다변량 시계열 (0) | 2024.11.13 |
| [강의 요약] 패캠 시계열 분석 - Part3. 본격 시계열 분석하기 (0) | 2024.11.13 |
| [강의 요약] 패캠 시계열 분석 - Part1. 데이터 분석 첫 걸음 떼기 (0) | 2024.11.12 |