

CNN은 어떻게 인간의 사고방식을 흉내냈나
- 신경 다발(connections)을 잘 끊어냄
- 이미지를 인식할 때 뇌의 일부분만 활성화 되더라는 실험 결과

- 과연 첫 layer에서 모든 필셀의 값을 다 보려는게 좋은 걸까? 아니라는 것!
- 위치별 특징을 추출함
- 이미지를 FC Layer에 넣으면 한 픽셀 한 픽셀 너무 세세하게 본다.


FC Layer에서는 왼쪽 그림이나 오른쪽 그림이나 학습 방식에서 차이가 없음
- CNN에서는 사전 정보(위치, 배치 등)을 가이드로 주고 학습하는 것과 비슷하다.
- 즉, 위치별 특징을 찾는 연산이다.





CNN은 어떻게 특징을 추출할까






100x100 이미지에 100x100 크기의 커널을 10개 사용하면 10000 입력 10 출력하는 FC Layer와 동일하다.
3D 이미지에 대한 Convolution

- Grouped Convolution
- Depth-wise Convolution

- Depthwise separable Convolution
- Point-wise Convolution

- 하나의 필터는 각 입력 채널별로 하나의 가중치만을 가지고 이 가중치는 해당 채널의 모든 영역에 동일하게 적용된다. 즉, 입력 채널들에 대한 Linear Combination과 같다.
- 등등
연습문제(긁으면 정답)
- 3x7x7 입력, 3x3 짜리 kernel의 채널 수? -> 3
- 그리고 그런 필터 10 종류 사용하면 출력 크기는? -> 10
- 그 다음 3x3 짜리를 또 conv한다고 했을 때 kernel의 채널 수? -> 10
- 그리고 그런 필터 20 종류 사용하면 출력 크기는? -> 20
- 위의 예시를 데이터 32개에 대해서 한다면? -> 상관 없음
- kernel size 가 1 x 1 이면 그건 뭘 하게 되는 걸까요..? ->
Padding & Stride & Pooling
- CNN이 반복되면 사이즈가 점점 줄어드는데, Padding을 쓰면 사이즈를 유지시킬 수 있다.


ㅇLinear Combination


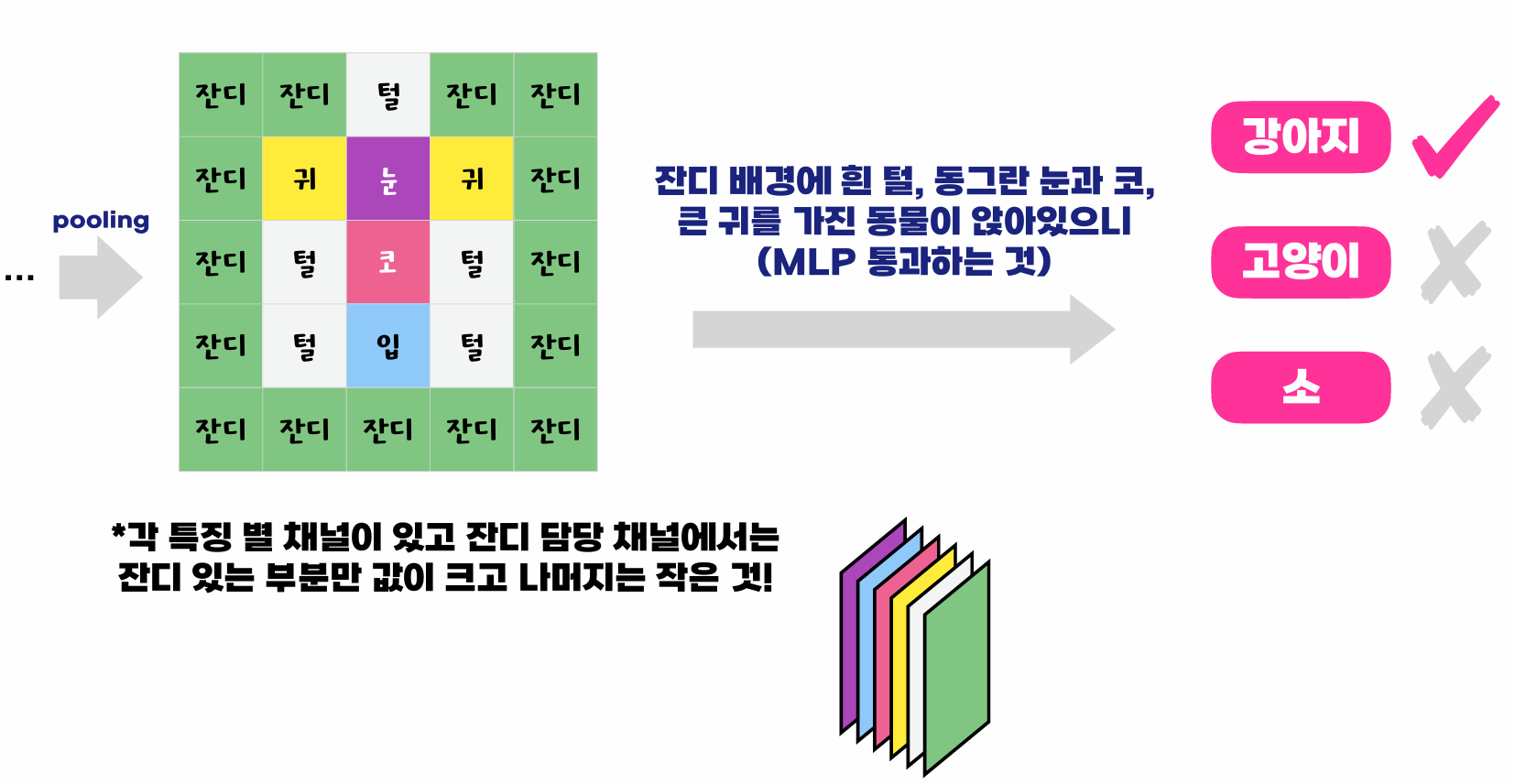




Block이 깊어질 수록 Max pooling 이 되어가니까, 지엽적이고 중요한 특징들이 뽑히는 느낌이다..



노란색 일수록 높은 숫자. 성공한 경우 배경보다 중요한 부분에 더 높은 숫자가 맵핑되는 것을 알 수 있음. 반면 실패할 경우, 중요하지 않은 곳에 히트맵이 높게 표시 된 것을 알 수 있다.

VGG Net 모델 읽기


Beautiful Insights for CNN


'인공지능 > [강의] 혁펜하임 딥러닝 강의' 카테고리의 다른 글
| Chapter 9. 왜 RNN보다 트랜스포머가 더 좋다는 걸까? (0) | 2024.12.15 |
|---|---|
| Chapter 7. 깊은 신경망의 고질적 문제와 해결 방안 (0) | 2024.12.12 |
| Chapter 6. 인공 신경망, 그 한계는 어디까지인가? (0) | 2024.12.10 |
| Chapter 5. 이진 분류와 다중 분류 (0) | 2024.12.01 |
| Chapter 4. 딥러닝, 그것이 알고 싶다. (0) | 2024.11.27 |