

Universal Approximation Theorem (왜 하필 인공신경망인가)
MLP는 \(f_2(f_1(WX+b))\)처럼 행렬 곱과 Activation 함수가 결합된 단순한 형태이다. 하지만 이론상으로, 히든 레이어 한개만 있으면 어떤 연속 함수든 만들어 낼 수 있다. 이것이 Universal Approximation Theorem 이며, 인공 신경망의 성공 요인이다.
예를 들어, 키가 입력이고 출력이 몸무게인 함수를 만든다고 가정하자.

위 그림 처럼 데이터 1개 당 2개의 노드만 있으면 loss를 0으로 만들 수 있다.
예를 들어, x=160, y= 60 이면,
가장 위의 노드를 통해서 60이 출력되고, 아래 모든 노드들은 step activation function에 의해 모두 0처리 되므로 x=160, y= 60이 성립된다..
즉, 두 개의 노드만 있으면 하나의 데이터 포인트를 그릴 수 있음.
첫 번째 노드는 해당 데이터 포인트의 값을 정확히 출력하고, 두 번째 노드는 더 큰 값이 들어왔을 때 정확히 정 반대 출력 값을 내놓아서 합을 0으로 만드는 역할(위 그림에서 함수가 깍두기처럼 생긴 이유...)


어떤 함수든 2개의 노드로 하나의 포인트를 그릴 수 있으므로 노드를 많이 만들면 어떤 함수든 만들 수 있다.
하지만 Fully-connected 1개의 층으로 모든 함수를 표현 한다는 것은 쉽지 않다.
예를 들어, a,b,c,d 가 입력이 되면 ac+bd (내적)가 출력이 되도록 만드는 것도 어렵다. 따라서 이 것을 Transformer에서 self-attention 연산을 추가 한 이유로 볼 수도 있다.
참고로 위 깍두기 예시에서 activation function을 step function으로했는데, sigmoid로 해도 상관없다. \(\frac{1}{1+e^-wx}\)에서 w 값이 커지면 거의 깍두기처럼 되기 때문에..
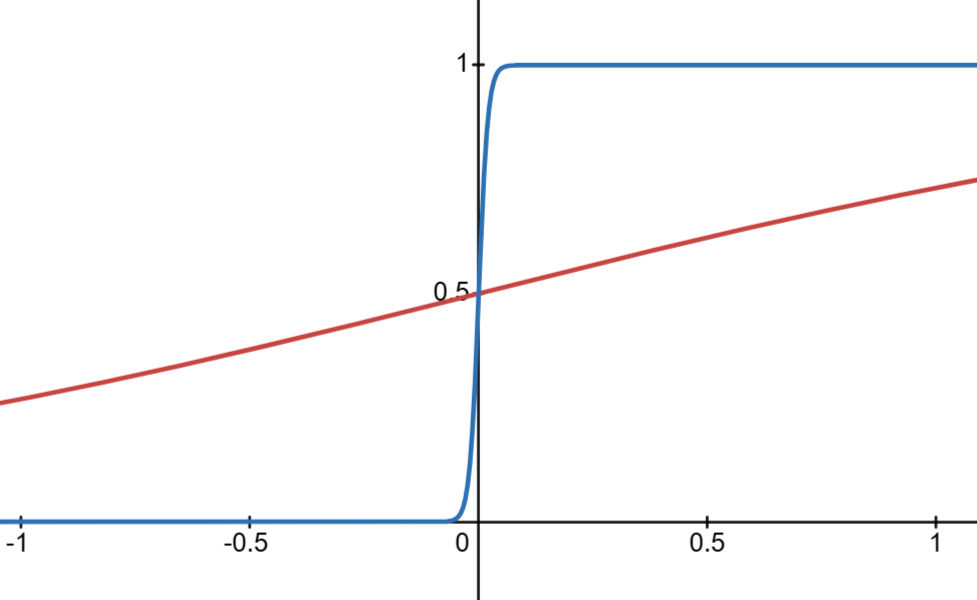
Universal Approximation Theorem에서 입력이 두개인 경우
입력이 두개면 깍두기도 3차원이 되면 된다.

Neural networks and deep learning
One of the most striking facts about neural networks is that they can compute any function at all. That is, suppose someone hands you some complicated, wiggly function, $f(x)$: No matter what the function, there is guaranteed to be a neural network so that
neuralnetworksanddeeplearning.com
실습
https://colab.research.google.com/drive/1H7d381rp-jiM7puWFW61AR4V83KK8-HM#scrollTo=msrpYBuWEKvg
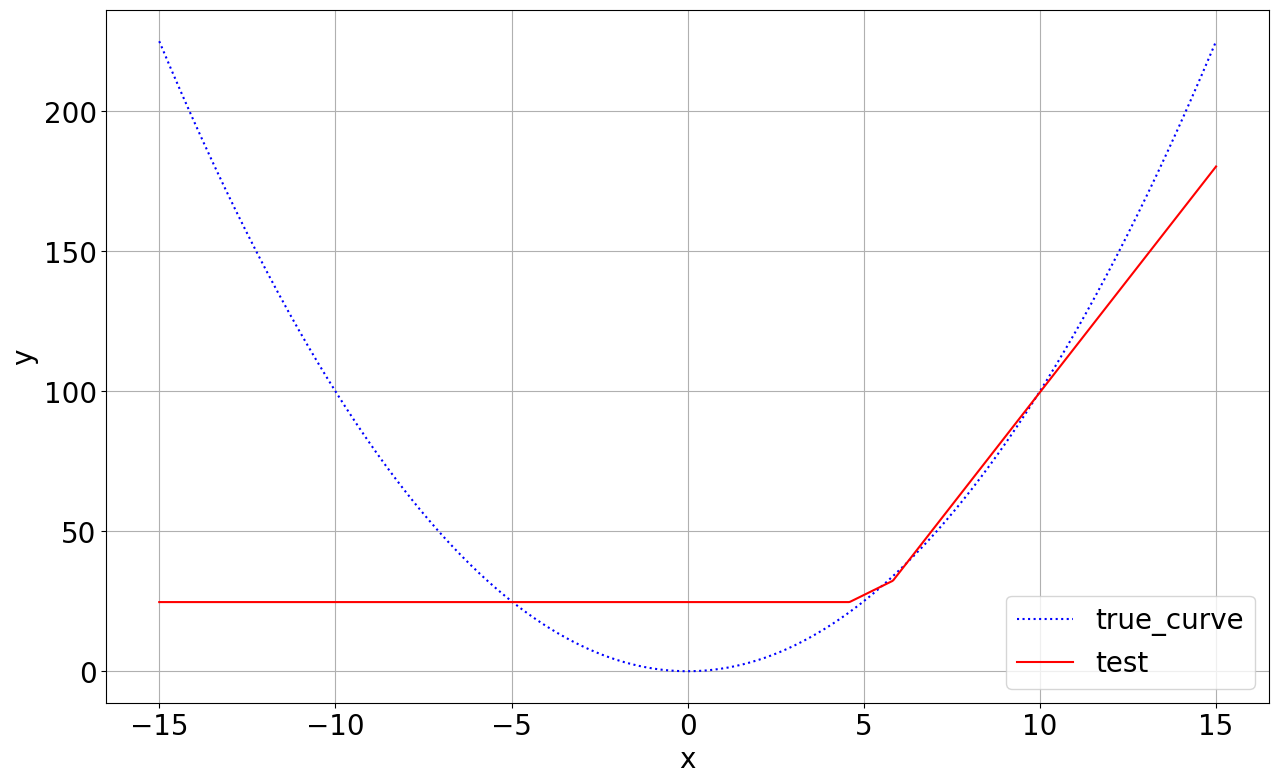
1개 층, 1000개 노드 테스트, (\(y=x^2\)) 함수 그리기,
- Train data = -10~10 사이 랜덤 숫자
- Test data = -15~15 사이 랜덤 숫자

Train 데이터에 속해 있던 -10~10 사이 구간은 잘 맞추지만 그 바깥은 잘 맞추지 못함.
왜 학습할 때 다양한 데이터가 필요한지 여실히 알 수 있는 실습인 듯.
층은 늘리되, 노드는 적게 하면 어떻게 될까
학습이 잘 안되는 것을 볼 수 있음
Beautiful insights for ANN
- ANN: Artificial Neural Network
- MLP는 행렬 곱하고 벡터 더하고 activation, 행렬 곱하고 벡터 더하고 activation, …
- 인공 신경망은 함수다
- 어떤 연속 함수든 다 표현 가능하다. (Universal approximation theorem)
- 원하는 출력 나오도록 (L을 줄이도록) 조금씩 가중치 값들을 update (gradient 반대 방향으로) 해 나가는 것. 그게 “AI가 학습을 한다”는 것의 실체다!
'인공지능 > [강의] 혁펜하임 딥러닝 강의' 카테고리의 다른 글
| Chapter 8. 왜 CNN이 이미지 데이터에 많이 쓰일까? (0) | 2024.12.14 |
|---|---|
| Chapter 7. 깊은 신경망의 고질적 문제와 해결 방안 (0) | 2024.12.12 |
| Chapter 5. 이진 분류와 다중 분류 (0) | 2024.12.01 |
| Chapter 4. 딥러닝, 그것이 알고 싶다. (0) | 2024.11.27 |
| Chapter 3. 인공신경망이란? (0) | 2024.11.26 |