

- 24년 하반기부터 휴직을 하게 되면서, AI 업계의 변화의 흐름을 잠시 떨어져서 바라볼 기회를 얻게 되었다.
- 휴직은 6개월의 짧은 기간이었지만, 돌아보니 OpenAI-O 시리즈, Agent 시대의 개막, 로봇(Phisical) AI의 재조명 등 눈여겨 볼만한 많은 변화가 있었다고 생각하여 그 내용들을 얕고 넓게 정리해보고자 함.
Overview

LLMs
24년 하반기에도 역시나 많은 Opensource LLM들이 등장하였다. 그 중에서 눈여겨볼 만한 LLM들을 정리하면 다음과 같다.
1. QWEN 2.5(10월)
- 알리바바에서 공개한 opensource LLM
- 한국어 포함 29개 언어 지원
- 32K~128K context length

- QWEN 72B 모델은 Llama-3-405B, Mixtral8-22B을 뛰어넘는 성능
- 유료 플래그쉽 모델도 공개, GPT4-O mini에 필적할만 함
2. Llama 3.3-70B-instruction(12월)
- 70B중 최고 성능, Llama 3.1 405B와 유사하거나 이상의 성능
- Tool-use, Multilinguality(8개 언어, 한글 X) 특화
- 여러 벤치마크에서 GPT4-O 와 유사한 성능
3. Phi-4(12월)
- MS, 14B 소형 언어 모델
- 소형 임에도 수학과 같은 complex reasoning task에서 대형 언어 모델을 능가하는 성능을 보임

- Context length: 16k tokens
- 💡핵심 기술 및 혁신:
- Pivotal Token Search: 중요 토큰만 처리해 최대 3배 속도 향상, 메모리 사용량 40-60% 감소.
- Multi-Agent Prompting & Self-Revision: 다양한 시나리오와 고품질 합성 데이터를 생성.
- Direct Preference Optimization: 2단계로 출력 품질을 최적화.
- Instruction Reversal: 새로운 학습 관점 제공으로 모델 다양성 증대.
4. Titans(12월)
- 구글에서 공개한 긴 문맥 처리에 특화된 Transformer의 대체자
- 2M context length 제공(Gemini는 1M이었고 아키텍처가 Transformer & MOE 구조였듯..?)
- self-attention을 통해 단기 기억을 처리하고, 신경망 메모리 모듈을 통해 장기 기억을 관리하는 듀얼 메모리 시스템
-
"surprise" 개념 도입
-
입력 시퀀스에서 예상치 못한 또는 놀라운 토큰을 우선적으로 기억 -> 인간의 기억 시스템에서 영감을 얻음
-
gradient가 클수록 입력 데이터가 과거 데이터와 다르다는 것을 나타내고 이것을 'surprise' 점수로 사용해서 메모리 업데이트 -> surprise 점수가 높을 수록 토큰을 잘 기억하도록 유도

BABILong benchmark - Agent나 DNA Sequence 처리 같이 초장문 Context가 필요한 영역에서 크게 활용될 것으로 기대
-
LLM Reasoning
LLM이 상대적으로 취약했던 Reasoning(추론) 능력을 향상시키기 위해, OpenAI O 시리즈를 필두로 많은 모델들이 쏟아지기 시작함.
OpenAI O 시리즈의 등장
- OpenAI O 시리즈는 최초의 "응답하기 전에 생각하는 모델"이며, 과학, 수학, 코딩 등 복잡한 작업에 중점을 두고 설계된 모델
- O1-preview는 GPQA(물리학, 화학, 생물학) 벤치마크에서 인간 박사 과정 수준의 점수 획득

- o1은 ‘추론 토큰’을 사용하여 문제를 내부적으로 처리하고 분석한 후, 이를 기반으로 최종적인 응답을 생성(따라서 입력 Prompt에 CoT를 임의로 추가하면 안됨)

- OpenAI는 12월에 '12 days of OpenAI' 세션을 통해 12일 연속으로 새로운 기능, 모델 출시
- 마지막날 공개한 O3는 AGI 평가 벤치마크에서 87.5점 기록(이전 모델인 GPT4-o 는 5점)
-> AGI를 달성한 것은 아니나 이제 진짜 AGI가 멀지 않았다는 것을 증명
O Series가 제시하는 새로운 패러다임
- '빠른 사고'에서 '느린 사고'로의 전환
- 사전 학습된 본능적 반응("시스템 1")에서 더 깊고 신중한 추론("시스템 2")으로의 도약
- 모델이 단순히 무언가를 아는 것에서 넘어서, 결정을 내리기 위해 잠시 멈추고, 평가하고, 추론 -> Agent 추론의 시대
-

https://www.sequoiacap.com/article/generative-ais-act-o1/ - Test-time(inference) Scaling Law
- O-Series는 그간의 Training time Scaling Law(Chinchilla law 등등)과는 다른 Test-time(infrence) Scaling Law를 새롭게 제시했다는 점에서 큰 의의가 있음.
- Test-time(inference)에 더 많은 자원을 투입할 수록 성능이 증가


- 마치 알파고가 MCTS 전략을 통해 바둑의 다양한 경우의 수를 생각했던 것처럼, O1은 다양한 추론의 경우의 수를 내부적으로 탐색하기 때문에 추론 컴퓨팅 리소스가 많이 필요하고, 그에 비례해서 성능이 향상됨.

CES 2025, 젠슨 황 키노트 중 Test-Time Scaling 에 관한 설명
DeepSeek-R1: 강화학습 기반 추론 모델
- 중국 스타트업 DeepSeek이 1세대 추론모델인 DeepSeek-R1-Zero와 DeepSeek-R1 모델을 공개
- DeepSeek-R1-Zero는 대규모 강화학습(RL)만으로 학습되었고, 스스로 다양한 추론 능력을 습득했음
- DeepSeek-R1은 수학, 코드, 추론 작업에서 OpenAI-o1 수준의 성능을 달성함
- DeepSeek-R1-Zero, DeepSeek-R1, distillation 모델들을 오픈소스로 공개

- 특히 DeepSeek-R1-Distill-Qwen-32B 모델은 OpenAI-o1-mini를 능가하는 성능을 달성했음

DeepSeek-R1의 강화학습 알고리즘의 특징
- Group Relative Policy Optimization (GRPO)
- GRPO는 PPO(Proximal Policy Optimization)와 달리 별도의 가치 함수 모델을 사용하는 대신 같은 질문에 대한 여러 출력 샘플의 평균 보상 사용
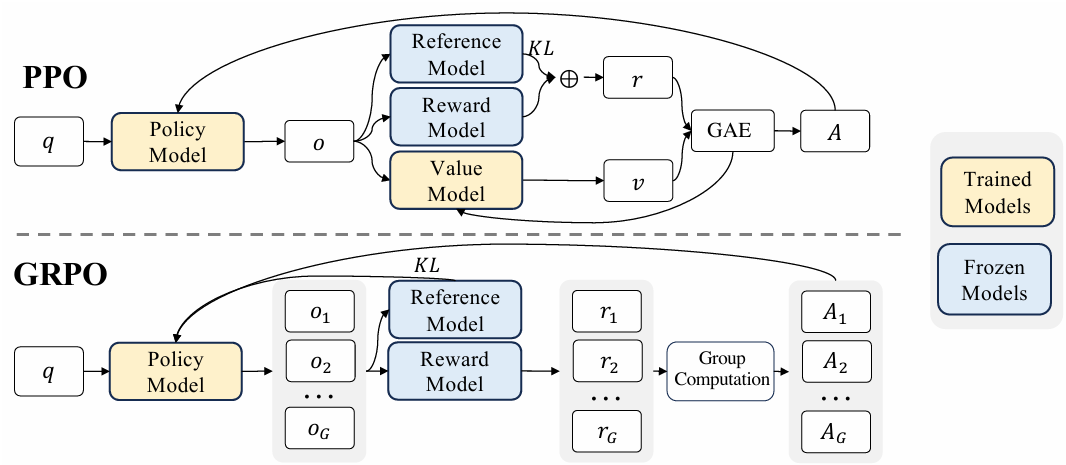
- 가치 함수를 사용하지 않기 때문에 학습 리소스 효율적이면서, 그룹 내의 상대적 보상으로 학습되므로 Advantage라는 상대적 보상을 통해 학습되는 RL의 특성과도 잘 부합됨
- Reward Modeling
- Accuracy rewards: 수학에서의 정답처럼 Rule based의 reward 사용.
- Format rewards: <think>, <answer>과 같이 형식에 맞게 답변을 할 경우 reward를 줌. <think> token을 사용함으로써 추론을 강제하는 효과
- 'aha moment'
- 'aha moment'는 모델이 기존의 접근 방식을 재평가하고 새로운 방식으로 문제를 해결하기로 결정하는 순간을 의미
-

- Supervised Signal 없이 오로지 Reward Signal만으로 모델이 스스로 고급 문제 해결 전략을 개발하도록 유도
-> 강화 학습이 모델의 추론 능력 향상에 얼마나 효과적인지를 보여주는 사례라고 주장
rStar-Math
- MS에서 25.1월에 공개한 연구
- 소규모 언어 모델(SLM)이 Monte Carlo Tree Search (MCTS)를 활용한 "심층적 사고(deep thinking)"를 통해 OpenAI-o1 이상의 수학적 추론 능력을 달성할 수 있음을 보여줌
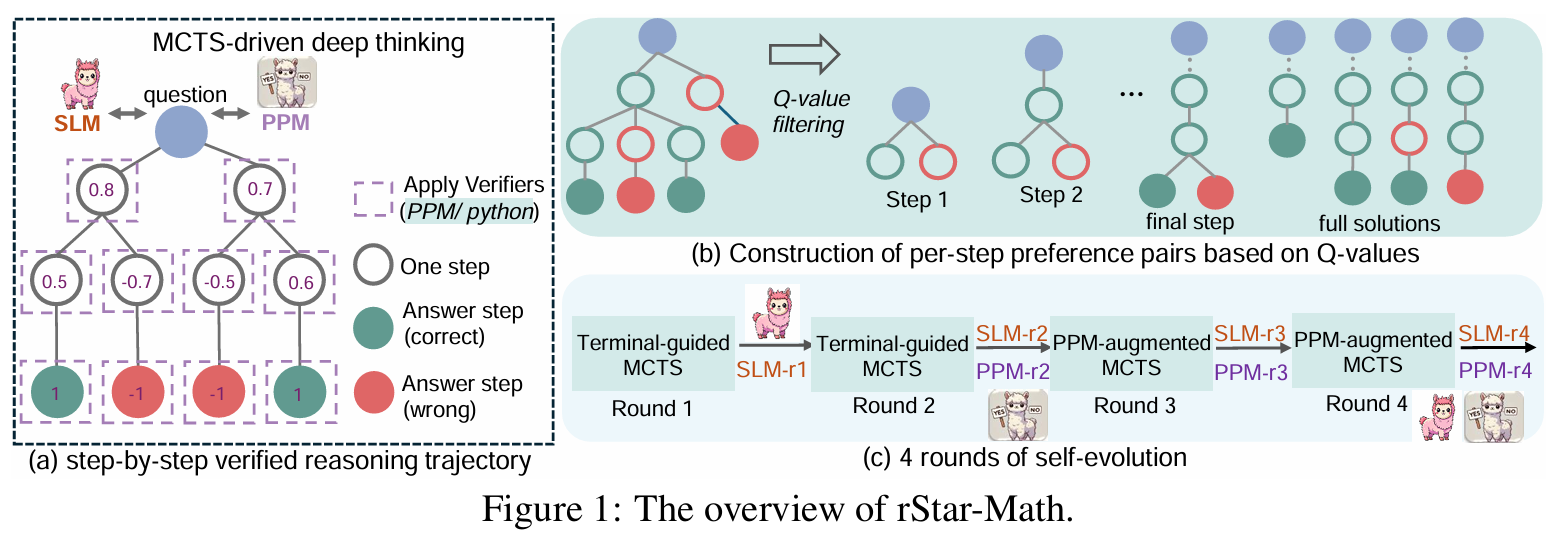
핵심 알고리즘
- 심층적 사고 (Deep Thinking) 메커니즘
- rStar-Math는 MCTS를 활용하여 수학 문제 해결을 여러 단계의 추론 과정으로 분해
- 정책 SLM은 추론 단계를 생성하고, 보상 모델은 각 단계를 평가하여 최종적으로 정확한 답을 도출
- 코드 증강 CoT (Code-Augmented CoT) 데이터 합성: 각 추론 단계에 대한 자연어 CoT(Chain-of-Thought)와 실행 가능한 파이썬 코드를 함께 생성함. 이 때, 파이썬 코드가 성공적으로 실행된 단계만 유효한 데이터로 간주하여 추론 단계의 정확도를 높임
성능 요약
- 7B SLM으로 OpenAI의 o1과 비등하거나 능가하는 수준의 수학적 추론 능력을 보여줌.

LLM Reasoning 발전의 시사점
Generative AI’s Act o1
The Agentic Reasoning Era Begins.
www.sequoiacap.com
- AI 경쟁에서 살아남으려면?
- 인프라 계층에서 경쟁하려면 NVIDIA와 하이퍼스케일러를 이겨야 함
- 모델 계층에서 경쟁하려면 OpenAI와 Mark Zuckerberg를 이겨야 함
- 애플리케이션 계층에서 경쟁하려면 기업 IT와 글로벌 SI 업체를 이겨야 함
- 애플리케이션 계층에서의 경쟁이 가장 실현 가능해 보임
- 생성 AI의 다음 단계에서는 추론 연구개발(R&D) 의 영향이 애플리케이션 계층에 빠르고 깊게 확산될 것으로 예상됨
- 연구실에서는 Reasoning과 Inference-Time의 계산이 계속 중요한 주제로 남을 것이며, 새로운 스케일링 법칙이 등장한 지금, 다음 경쟁이 시작됨
- 많은 사람들이 기대하는 순간은 생성 AI의 ‘Move 37’ 로, 이는 AlphaGo가 이세돌과의 대국에서 보여준 것처럼 일반 AI 시스템이 예상치 못한 초인적인 행동을 보이는 순간을 의미함
- 이 순간이 온다고 해서 AI가 “의식을 가지는” 것은 아니지만, AI가 지각, 추론, 행동의 과정을 시뮬레이션하여 독창적이고 유용한 방식으로 탐색할 수 있는 능력을 가질 수 있음
- 이는 AGI(인공지능의 완전한 자율성) 일 가능성이 있으며, 이는 단일한 사건이 아니라 기술의 다음 단계로 이어질 것임
Agentic AI
Agent 시대의 도래
- ChatGPT 등장 이후 AI Agent에 대한 관심이 폭발함(사실 이전에는 강화학습 필드에서만 Agent라는 용어를 사용..)
- NeurIPS 2024에 제출된 논문 중 106개의 논문이 AI Agent 를 다루었음


- 더욱 최근에 와서, Agent보다 더 높은 자율성과 상황 인식, 적응력을 갖춘 AI 모델을 Agentic AI라고 부르기 시작

- Agentic AI(보다 복잡, 상황이 계속 변함)
- 환경에 따라 주행을 조정하는 자율주행 자동차
- 의료 데이터를 분석하고, 패턴을 식별하며, 의사가 더 정보에 입각한 결정을 내릴 수 있도록 돕는 헬스케어 시스템
- AI Agent
- 알림을 설정하고, 날씨를 확인하고, 좋아하는 음악을 틀어주는 개인 비서 앱
- 코드 작성을 돕는 Copilot
Agent 시장을 향한 기업들의 움직임
- 자사의 Agent를 공개하는 것을 넘어, Agent Platform을 만들고 싶어하는 기업들
- MS, 에이전트를 고객이 직접 개발할 수 있는 기능인 코파일럿 스튜디오 공개
- NVIDIA 젠슨 황, 2025 CES에서 AI 에이전트 시대의 도래를 선언하며, NeMo와 NEM 마이크로서비스를 통해 기업들이 맞춤형 AI 에이전트를 구축할 수 있는 플랫폼 공개

- Antropic은 지난해 10월 챗봇 '클로드3.5 소네트' 모델에 클릭과 스크롤, 타이핑 처럼 컴퓨터를 사용할 수 있는 기능을 장착한 AI Agent 모델 발표
- AWS, 트랜스포머 창업자가 만든 Agentic AI 개발 스타트업 'Adept' 인수
- 타임지, 올해 AI의 트렌드는 'AI 에이전트'
- 자체 RPA를 솔루션을 가지고 있는 삼성SDS의 경우, Agent AI를 개발 안 할 이유가 없지 않을까 하는 개인적인 생각..
Robot(Physical) AI의 ChatGPT 모먼트
- 젠슨 황, 2025 CES 기조 연설에서 물리 세계를 완벽히 시뮬레이션 할 수 있는 디지털 트윈 플랫폼 '코스모스' 공개
--> 로봇 AI에서의 ChatGPT 모먼트가 도래했다고 말함 - Cosmos는 물리적 세계의 데이터를 이해하고 시뮬레이션하는 'World Foundation Model'의 일종
- 물리적 세계에서 발생하는 데이터와 현상을 AI 모델이 학습하고 활용하도록 지원
- 로봇, 자율주행차, 산업용 AI 등 다양한 물리적 AI 응용 분야에서 사용
- '프롬프트'를 입력하면 가상 3D 환경으로 구현된 영상을 생성 -> 생성된 영상 데이터를 통해 로봇과 자율 주행차 훈련 효율성을 극대화

- 엔비디아의 "원숭이 꽃신 전략"
- 무상 제공→소비자 노예화→유료 전환
- 엔비디아 없이는 AI를 개발할 수 없게 만드는 ‘원숭이 꽃신 전략’을 로봇에도 구현
- https://www.youtube.com/watch?v=eJedH3s0lUE&t=608s