

엔비디아 주가를 20%나 폭락시킨 중국 DeepSeek-R1 모델을 파헤쳐보고자 한다.
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Abstract
이 논문에서는 DeepSeek(중국 스타트업)의 첫 번째 reasoning model인 DeepSeek-R1-Zero와 DeepSeek-R1을 공개한다. 이 말에서부터 Reasoning이 아닌 다른 타입의 model은 이미 공개 된 상태란 것을 알 수 있다.
특히 R1-Zero는 지도 학습 없이 순수한 강화학습으로만 학습 되었음을 강조하고 있다(ChatGPT류의 시작인 InstructGPT, LLaMa 등은 대부분 지도 학습 이후 강화학습을 이어서 진행하는 방식이다).
그러나 R1-Zero는 강화학습만으로 Reasoning(복잡한 추론) 능력은 갖출 수 있었으나, 영어와 중국어를 Mixing 한다거나 가독성이 떨어지는 답변을 내뱉는 등 기본적인 대화 능력이 떨어지는 단점이 있었다. 이를 보완하기 위해 본 논문에서는 multi-stage training과 cold-start 기법을 활용하여 DeepSeek-R1 모델을 공개하고 있다.
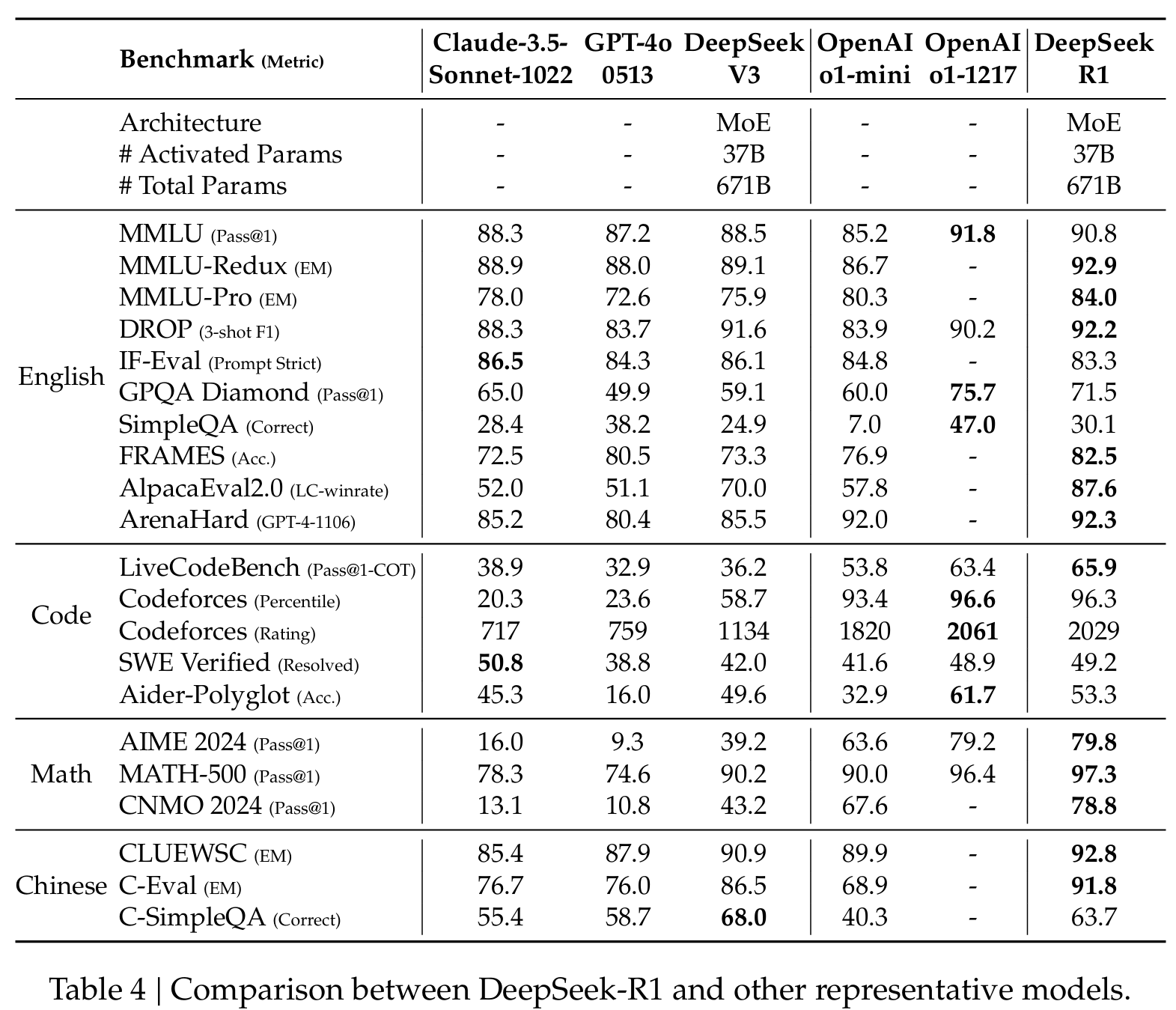
DeepSeek-R1은 'OpenAI-o1-1217'과 비교하여 비벼볼만한(comparable)한 성능을 보였다. o1의 reasoning 성능이 워낙 시장에서 센세이셔널 했기 때문에 o1 모델의 성능과 비교한 것 같다.
그리고 제일 대단한건, 모든 모델의 weight를 공짜로 공개했다는 점. (distilled model도 공개 1.5, 7, 8, 14, 32, 70B)

Introduction
OpenAI o1 시리즈가 보여준 inference-time scaling을 통한 LLM의 Reasoning 능력 향상은 업계에 큰 반향을 불러일으켰으나, 그 비용적 효용성 면에서 아직 의문점이 남았다. 그리고 o1을 따라잡기 위한 많은 시도들(process based RL 이나 MCTS를 활용하는 방법 등)이 있었으나 아직 o1의 수준에 이르는 결과는 없었다.
이런 배경에서 본 논문에서는 순수하게 RL만을 활용해서 o1 수준의 Reasoning 성능에 도달할 수 있음을 보이고 있다.
이를 위해서 DeepSeek-V3(이전 모델)를 base 모델로 사용하고 GRPO라는 강화학습 알고리즘을 활용한다. 그러나 이렇게 학습 된 모델인 DeepSeek-R1-Zero는 Reasoning 벤치마크에서 o1 수준의 성능을 보였으나, 가독성이 떨어지고 여러 나라의 언어를 섞어서 말하는 단점이 발생했다.
저자들은 이러한 R1-Zero의 문제를 해결하기 위해 cold-start data와 multi-stage training을 적용하여 DeepSeek-R1을 탄생시켰다. 일단 이전 모델인 V3 모델을 적은 양의 cold-start data로 fine-tuning 한 뒤, Zero에서 사용된 것과 같은 reasoning-oriented RL을 진행한다. 또한 RL이 convergence에 가까워지면 추가 SFT를 하는데, 여기서는 V3를 학습할 때 쓰였던 non-reasoning 데이터(writing, factual QA 등)와 RL checkpoint로 Rejection Sampling을 진행하여 얻은 데이터를 합성해서 사용한다. 마지막으로 SFT가 끝나면 지금까지 사용된 모든 Prompts를 활용하여 최종 RL을 한 번더 진행한다.
이 과정이 모두 끝난 모델을 DeepSeek-R1이라 부르고 이 모델은 OpenAI-o1-1217과 대등한 성능을 보였다.
마지막으로 DeepSeek-R1을 이용해서 Qwen과 LLaMa를 대상으로 distillation 진행한 결과를 제시한다. 여기서 중요한 점은, Qwen을 RL로 학습한 것보다 DeepSeek-R1의 답변을 뱉도록 direct distillation(그러니까 일반적인 SFT?)를 한 것이 더 좋다는 것이다. 즉, 굉장히 훌륭한 LLM이 발견한 reasoning pattern이야 말로 reasoning capability를 향상시키는데 가장 중요하다는 것이다.
이 논문의 Contribution을 간단히 요약하면,
- Post-training: Large Scale Reinforcement Learning on the Base Model
- DeepSeek-R1-Zero: SFT없이 RL만으로도 복잡한 문제를 해결하는 Reasoning 모델을 학습할 수 있음을 증명
- DeepSeek-R1: Reasoning뿐만 아니라 Human Preference에도 잘 맞는 응답을 생성할 수 있는 새로운 Pipeline 제시
- Distillation: Smaller Models Can Be Powerful too
- Large Model의 Reasoning Pattern이 더 작은 모델에게 효과적으로 전이될 수 있음을 증명
Approach
우선 SFT없이 모델의 Reasoning 능력을 향상시키기 위해 사용한 방법인 GRPO에 대해서 알아보자.
Group Relative Policy Algorightm
- 목적 함수
- GRPO에선 일단 Critic 모델을 사용하지 않는다. 대신 baseline을 group score로 대체한다.
- 질문 q에 대해서 \(\pi_{\theta_\text{old}}\)를 활용하여 \(\{o_i\}_{i=1}^G\)를 추출하고, 위의 목적 함수를 최대화 하도록 \(\pi_{\theta}\)를 학습한다.

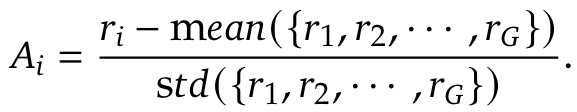
- Reward Modeling
- 특이하게 Rule-Based Reward System을 사용한다. 즉 뉴럴넷 리워드 모델을 사용하지 않는다.
- Rule-based Reward System은 다음 두 가지 타입이다.
- Accuracy rewards: 수학과 같은 deterministric results를 가진 문제에 대해서 response가 정답인지 확인하여 정확도를 리워드로 사용(더 디테일한 내용은 없음). 혹은 코딩 문제는 test case를 활용하여 feedback으로 사용할 수 있다.
- Format Rewards: 모델이 thinking process를 '<think></think>' 토큰 사이에 넣을 수 있도록 강제하기 위해 format 리워드를 사용한다.
- 이 외에 뉴럴넷이나 process reward model은 사용하지 않는다. 그 이유는 large-scale RL의 경우 reward hacking 문제가 발생 할 수 있을 뿐 아니라 reward model 자체를 학습하는데 굉장히 번거롭기 때문.
<여기에 대한 나의 생각>
DeepSeek-R1-Zero에서 이해가 되지 않는 점
1. 학습 데이터에 대한 구체적 언급이 없다.
: 보통 RL을 하는 이유는 레이블링이 어려운 Task에서 환경이 주는 Reward를 레이블 대신 사용하기 위해서이다.
그러니 레이블링 데이터가 풍부한 Task에서는 굳이 RL을 할 필요가 없다.
근데 DeepSeek-R1-Zero는 정답이 명확한 수학과 같은 데이터로 Rule-Based Reward RL을 했다고 한다. 즉, 레이블이 되어있는 데이터로 RL을 했다는 이야기로 들린다. 그렇게 명확한 답이 있는 문제에 대해서 왜 RL을 했을까? Process Reward도 안 쓰면서?
GRPO가 좋으니까 RL을 썼다고 한다면, 어떤 데이터를 얼마나 썼는지 언급이라도 해야할텐데 왜 없을까.. 레이블이 있는 데이터는 거의 유료이기 때문에 이 데이터 확보에 사용한 돈도 사실상 80억에 포함 시켜야 할 것 같은데 말이다..
2. <think></think>에 대한 의구심
: R1-Zero는 format reward를 통해서 모델의 답변에 <think>~~</think> 만 포함시키면 그 안의 내용이 무엇이든 무조건 리워드를 주는 것 같다.
<think> tag 안의 내용에 대한 직접적인 training signal 없이도 정답만 맞추도록 학습을 시키면 모델이 자연스럽게 '<think></think>' 안에 적절한 process를 담게 된다는 이야기 같은데, 그건 연구자의 희망 사항이지 실제로 반드시 그렇게 되리라는 보장은 없다고 생각한다.
Meta에서 나온 COCONUT도 '<bot>...<eot>' 토큰 사이에 모델의 생각을 강제로 집어넣기 위해 CoT의 한 step씩 제거하면서 학습을 진행 해서 단계적으로 천천히 생각을 집어넣도록 힘겹게 유도한다.
그리고 format reward만큼 reward hacking이 쉬운 것이 없다. <think> 토큰만 뱉으면 무조건 리워드를 받기 때문에, 1에폭도 아니고 몇십 스텝만에 바로 reward hacking이 일어날 것 같은 느낌이다.
왠지 <think> 토큰을 format 강제 효과 이상으로 활용할 수 있는 방법이 향후에 많이 나올 것 같기도..
Training Template
모델에게 instruction을 이해하기 위한 힌트를 주기 위해 다음과 같은 structural template을 사용한다. 반면 어떤 형태로든 content-specific bias가 주입되는 것을 막기 위해 다른 프롬프트는 사용하지 않았다.

Performance, Self-evolution Process and Aha Moment of DeepSeek-R1-Zero
Performance
강화학습 만으로 학습된 R1-Zero는 수학 테스크에서 o1-mini를 능가하고 o1-0912와 대등한 성능을 보인다. 다만 코딩 테스크에서는 아직 많이 미달하는 모습이다.


여기서 궁금한 점,
다른 논문에서는 많은 경우에 과거의 AIME데이터를 학습 데이터로 사용한다. 가령 AIME 2023말이다. R1-Zero에서도 이 것을 사용했을까?
그리고 MATH-500은 이미 점수가 90~95점 이상으로 난이도가 매우 쉬운 문제이기 때문에, 큰 변별력이 없어 보일 수 있다.
Self-evolution Process of DeepSeek-R1-Zero
저자들이 가장 들떠서 주장하는 부분이 바로 이 부분이 아닌가 싶다. SFT를 한 뒤에 RL을 하는게 아니라 바로 RL을 함으로써 얻게 되는 이점이라고 할 수 있을 것이다.

Figure 3를 보면 우선 학습 스텝이 증가할 수록 response 길이가 증가하는데, 저자들은 이처럼 모델의 thinking time이 저절로 늘어나는 것이 reasoning capability가 증가하고 있다는 증거라고 주장한다.
또한 강제로 시킨것도 아니지만 모델이 스스로의 생각을 다시 되짚어보는(reflection) 행동을 취하게 되는데, 이런 self-evolution이야 말로 강화학습의 가장 큰 효과라고 주장한다.
Aha Moment of DeepSeek-R1-Zero
학습이 진행되는 중간 과정에서, 다음 그림처럼 모델이 스스로 다시 자신의 접근법을 되짚어 보는 순간이 등장했다. 저자들은 이러한 모델의 자연스러운 창발적 행동이야 말로 RL의 power and beauty이며, AI를 다음 레벨로 끌어올려줄 열쇠라고 설명한다.

(중국이라서 그런가.. 왜이렇게 믿기지가 않지? answer reward만 주는데 어떻게 이런 현상이 일어났을까..)
Drawback of DeepSeek-R1-Zero
R1-Zero가 강력한 Reasoning 성능을 보여줬지만 나쁜 readability와 language mixing 문제가 발생. 이를 해결 하기 위해 cold-start 데이터를 활용하여 조금 더 인간이 선호할 만한 답변을 만들어 내도록 유도한다.
DeepSeek-R1: Reinforcement Learning with Cold-start
Cold start data
R1-Zero가 보여주었던 RL 방식의 단점을 극복하기 위해, 소량의 양질 데이터인 cold-start 데이터를 활용하여 초기 학습을 진행하였다. base 모델은 마찬가지로 DeepSeek-V3-base를 사용한다.
- 데이터 수집: R1-Zero에게 긴 CoT를 예시로 주고 reflection과 verification이 포함된 답변을 생성하도록 유도하고, human annotator들이 추가 검수를 하여 수천개 수준의 양질의 데이터를 획득한다.
- Readability: R1-Zero 때와 달리, output format을 지정해줌으로써 readability 향상을 유도했다.
- |special_token|<reasoning process>|special_token|<summary>
Reasoning-oriented Reinforcement Learning
이 단계에서는 DeepSeek-V3-base의 cold-start training이 끝나고, R1-Zero와 마찬가지로 large-scale RL을 진행한다.
cold-start data를 활용했음에도 불구하고, prompt에 여러 언어가 섞인 경우, 답변에도 여러 언어가 혼합되서 나오는 문제가 발생했다. 따라서 여기서는 a language consistency reward(답변에 포함된 target 언어의 비율을 리워드로 환산)를 적용하여 accuracy reward와 함께 사용했다.
Rejection Sampling and Supervised Fine-Tuning
이전에 수행한 cold start data 학습과 RL은 모델의 reasoning 능력을 올리기 위함이었다면, 이 단계에서는 일반적인 글쓰기나, 롤플레잉 능력과 같은 general-purpose task에 대한 학습을 진행한다. 학습을 위한 데이터는 다음과 같이 생성한다.
- Reasoning Data: 이전 RL에서는 rule-based reward만을 사용하였다. 반면 이번 단계에서는 generative reward model(DeepSeek-V3 사용한듯?)을 사용한다. 그리고 여러번 질문을 하여 여러 답변을 얻고, 그 중에서 language mixining 이나 가독성이 떨어지는 답변들은 모두 제거하고 하나의 답변만을 사용한다(총 600K)
- Non Reasoning Data: 글쓰기나 QA, self-cognition, 번역과 같은 질문은 DeepSeek-V3를 학습할 때 사용한 pipeline을 그대로 활용한다. V3를 활용하여 CoT가 포함된 답변을 생성하도록 유도한다. (총 200K)
- Resoning/Non Reasoning Data를 합쳐서 총 800K의 데이터로 V3-Base를 2 epoch 학습한다.
Reinforcement Learning for all Scenarios
여기서는 좀 더 Human prefence(Helpfulness & Harmlessness)에 맞는 답변을 생성하기 위해 두번째 RL을 진행한다. 물론 Reasoning 능력도 함께 향상시킨다.
Reasoning Data를 위해서는 R1-Zero 때와 마찬가지로 rule-based reward를 사용한다(대체 레이블 데이터가 몇개인건데??)
General Data는 Reward Model을 활용하며, V3-Pipeline과 유사한 데이터 분포를 갖는 Preference Pairs 데이터와 Prompt를 사용한다.
특이한 점은, helpfulness를 평가할 때는 summary의 내용만 평가하며,(위에서 언급했듯이 summary를 출력하는 output format이 존재)하고, harmlessness를 위해서는 전체 내용을 평가함으로써 서로 간섭 받지 않도록 했다.
Distillation: Empower Small Models with Reasoning Capability
작고 효율적인 모델을 만들기 위해, QWEN과 Llama 시리즈에 위에서 만든 800k 샘플을 SFT로 학습함.
(정확하지는 않은데 800K의 질문을 사용해서 R1으로 답변을 뽑았다는건지 무슨 말인지 모르겠네..)
- 모델 리스트: Qwen2.5-Math-1.5B, Qwen2.5-Math-7B, Qwen2.5 14B, Qwen2.5-32B, Llama-3.1-8B, and Llama-3.3-70B-Instruct.
Experiment

Distillation의 경우 7B 이상부터 성능이 급격히 상승
Discussion
Distillation vs RL

Distillation과 RL의 성능 비교를 위해 Qwen-32B에 대하여 RL과 R1을 활용한 Distillation을 진행함. 결과는 위에서 보듯이 Distillation의 성능이 훨씬 좋았다. RL을 10K만 했다고 되어있는데, 더 진행한다면 결과는 달라질 수 있지만 어쨌든 강력한 teacher 모델이 있으면 손쉽게 Distillation을 통해 매우 높은 성능을 보일 수 있음을 확인하였다.
Unsuccessful Attempts
- Precess Reward Model: Process Reward Model은 다음과 같은 이유에서 사용하지 않았다. 1) 일반적인 추론에서 단계를 명확히 정의하기 어려움. 2) 중간 단계가 옳은 단계인지 아닌지 판단하기 어려움. 3) 자동 annotation은 성능이 부족하고, 수동으로 하기엔 대량으로 할 수 없음
- MCTS: 알파고/알파제로에서 사용한 MCTS를 사용하여 답변을 작은 부분으로 나누고 체계적으로 solution space를 탐색하려는 시도를 하였다. 그러나 체스나 보드게임과 달리 token 생성은 search space가 너무 광범위하여 탐험하기 어렵고, token length를 제한하면 local optimal에 빠질 수도 있다. 또한 각 스텝을 평가하는 Value Model을 잘 만드는 것이 매우 Challenging하다.
Conclusion, Limitation, and Future Work
본 연구에서 RL 만으로 o1-mini 수준의 reasoning 능력을 보이는 모델을 만들었다는 것과 distillation으로 역시 강력한 small 모델을 만들 수 있음을 증명하였다. 다음은 Future Work이다.
- General Capbability: R1이 V3보다 function calling, multi-turn, complex role-playing, and json output 등에서 오히려 성능이 뒤쳐지는 경우가 있음
- Language Mixing: 여전히 중국어와 영어를 섞어서 쓰는 문제가 있음
- Prompt Engineering: R1이 Prompt에 따라 민감하게 반응하는 점을 발견함(그냥 전체적으로 robust 한 느낌은 아니네..)
- Software Engineering tasks: RL process에서 너무 시간이 오래 걸리는 관계로 SW task에 대해서는 학습이 광범위하게 이루어지지 못함.
나의 소평
- RL 과정에 대해서 학습 데이터에 대한 내용이 너무 없다.
- Reasoning 외에 다른 Task에 대해서는 직접 써보지 않는 이상 성능을 판단하기 어려울 것 같다.
- 전체 Pipeline에서 엄청 대단한거나 새롭다고 느껴지는 부분은 없다.
- 그래도 answer reward 만으로 RL을 하는 것이 가능하다고 주장하는 부분은 큰 시사점인 것 같다.