[논문요약] Chat Vector: Enhancing LLMs via Simple Model Arithmetic
저자
- Shih-Cheng Huang 외
- National Applied Research Laboratories, Taipei, Taiwan
한 줄 요약
- 간단한 벡터 연산(덧셈/뺄셈)을 통해 새로운 언어에 대한 instruction following 능력과 human value alignment 능력을 부여하는 방법을 제시
풀고자 하는 문제
- 대부분의 오픈 소스 대규모 언어 모델(LLM)은 데이터 제약으로 인해 주로 영어에만 특화
- 비영어권 사용자가 LLM을 처음부터 구축하는 것은 계산 비용이 많이 소요
- 기존의 방법대로 비영어권 LLM을 구축하려면 continual pretraining, SFT, RLHF 등의 복잡한 과정을 거쳐야 함
- 특히 RLHF는 구현이 복잡하고 많은 컴퓨팅 자원을 요구하며, 안정성 문제도 있음
- 인간 선호도에 맞추기 위해 복잡한 RLHF 과정을 거치지 않고 새로운 언어에 대한 모델을 정렬하는 방법이 필요
제안하는 방식
- Chat Vector라는 개념을 도입하여, 사전 학습된 기본 모델(예: LLaMA2)과 해당 챗 모델(예: LLaMA2-chat)의 가중치 차이를 이용하여 Chat Vector를 추출
- Continual Pretraining(CP)을 통해 Target language(예를 들어 한글)를 습득한 모델에 위에서 구한 Chat Vector를 더하여 새로운 언어에서 챗 기능을 활성화
- 기존의 CP → SFT → RLHF 방식 대신 CP + 챗 벡터 방식으로 간단하게 모델을 개선
- 이 방법은 추가 학습 없이 모델의 파라미터 공간에서 벡터 연산만으로 새로운 언어에 대한 대화 능력과 안전성을 확보할 수 있음
실험 결과
- 챗 벡터를 추가한 모델이 instruction following 능력, Toxicity 완화 능력, 멀티턴 대화 능력에서 성능 향상
- 베이스라인 모델
- Traditional Chinese LLaMA: 영어 LLaMA에 중국어 corpus(3.1B Tokens)으로 CP 한 모델.
- Chinese-LLaMA는 다른 논문에서 공개한 중국어 버전의 LLaMA
 실험 결과
실험 결과
- CP 후에 챗 벡터를 추가하는 것이 LLaMA2-chat을 직접 사전 학습하는 것보다 더 나은 결과를 얻었음
- 당연한거 아닌가? Chat 모델에다가 다시 프리트레이닝을 해버리면 catastropic forgetting이 일어날 것 같은데..
- 특이한 점은 Chat에 CP + FT 한게, LLM+CP+FT 보다 더 좋다는거.. catastropic forgetting이 Chat에서 많이 삭제가 안되고 여전히 남아있어서 그럴까?
- Fine-tuning을 한 후에 챗 벡터를 추가하면 FT 데이터셋의 크기나 LLM의 언어에 관계없이 성능이 향상
- 가장 Promissing 한 결과 같다. 어쨌든 ChatVector를 단순히 더하는 것 만으로도 성능이 향상 됨을 입증한 것이니까.
- 챗 벡터는 언어 능력과 지식 기반 측면에서 catastrophic forgetting을 유발하지 않았음
- TMMLU+ 벤치마크를 사용하여 모델의 지식 보존 능력을 평가
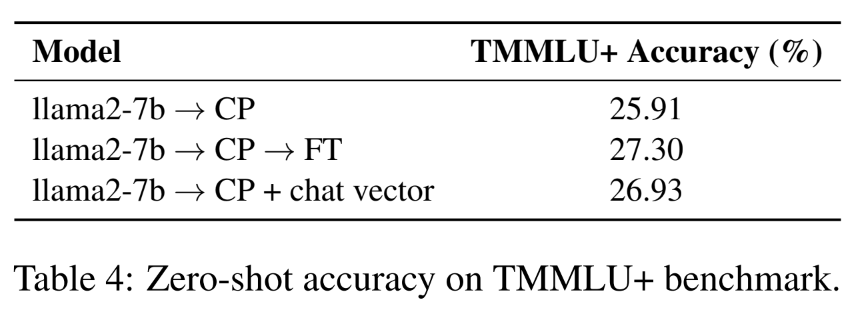
- 그러나 점수가 상승하지는 않았음. CP+FT+CV 는 왜 결과가 없을까?
- 중국어 외 한국어에도 적용해보았으나 동일한 효과가 있었음
- 챗 벡터는 여러 모델이 대화 기능을 빠르게 얻을 수 있도록 하며, RLHF를 재구현하는 것보다 계산적으로 더 효율적
- 챗 벡터를 추가한 모델은 안전성 평가, 멀티 턴 대화 능력 향상
한계점 및 향후 과제
- 챗 벡터를 추가했을 때 모델이 목표 언어 대신 영어로 응답하는 경우가 발생함. 이는 챗 벡터의 가중치를 조절함으로써 완화할 수 있지만, 최적의 가중치를 찾는 연구가 필요
- 자동 평가에만 의존하고 있어 응답에 대한 human evaluation 필요
- LLaMA2-chat의 RLHF 학습 데이터를 얻을 수 없어 RLHF와의 직접적인 비교가 불가능
내 생각
- 단순히 모델의 가중치를 더하는 것만으로도 성능이 향상되는 것이 놀라움
- 그러나 실험 결과가 CP/FT를 어떻게 하느냐에 따라서 많이 달라질 것 같음(제안 방식의 성능이 그렇게 크게 상승하지도 않았으니..)
- ChatVector를 더하고 추가적인 학습을 조금이라도 해보면 어땠을까?



